Spring Boot操作数据库
SpringBoot操作数据库
1.整合JDBC
SpringData简介
对于数据访问层,无论是 SQL(关系型数据库) 还是 NOSQL(非关系型数据库),Spring Boot 底层都是采用 Spring Data 的方式进行统一处理。
Spring Boot 底层都是采用 Spring Data 的方式进行统一处理各种数据库,Spring Data 也是 Spring 中与 Spring Boot、Spring Cloud 等齐名的知名项目。
Sping Data 官网:https://spring.io/projects/spring-data
数据库相关的启动器 :弹簧启动参考文档 (spring.io)

整合JDBC
- 导入测试数据库
1 | CREATE DATABASE /*!32312 IF NOT EXISTS*/`springboot` /*!40100 DEFAULT |
- 新建一个项目测试:springboot-data-jdbc; 引入相应的模块!基础模块

- 项目建好之后,发现自动帮我们导入了如下的启动器:
1 | <dependency> |
- 编写yaml配置文件连接数据库;
1 | spring: |
- 配置完这一些东西后,就可以直接去使用了!因为SpringBoot已经默认帮我们进行了自动配置;去测试类测试一下:
1 |
|
- 结果:可以看到他默认给我们配置的数据源为: class com.zaxxer.hikari.HikariDataSource,我们并没有手动配置。

- 来全局搜索一下,找到数据源的所有自动配置都在:DataSourceAutoConfiguration文件:
1 |
|
- 这里导入的类都在 DataSourceConfiguration 配置类下,可以看出 Spring Boot 2.6.3默认使用 HikariDataSource 数据源,而以前版本,如 Spring Boot 1.5默认使用 org.apache.tomcat.jdbc.pool.DataSource 作为数据源;
- ==HikariDataSource 号称 Java WEB 当前速度最快的数据源,相比于传统的 C3P0 、DBCP、Tomcat jdbc 等连接池更加优秀==;
- 可以使用 spring.datasource.type 指定自定义的数据源类型,值为要使用的连接池实现的完全限定名。
- 关于数据源不做过多介绍,有了数据库连接,显然就可以CRUD操作数据库了。但是仍需要先了解一个对象——
JdbcTemplate。
JdbcTemplate
- 有了数据源(com.zaxxer.hikari.HikariDataSource),然后可以拿到数据库连接 (java.sql.Connection),有了连接,就可以使用原生的 JDBC 语句来操作数据库;
- 即使不使用第三方第数据库操作框架,如 MyBatis等,Spring 本身也对原生的JDBC 做了轻量级的封装,即
JdbcTemplate。 - 数据库操作的所有 CRUD 方法都在 JdbcTemplate 中。
- Spring Boot不仅提供了默认的数据源,同时默认已经配置好了 JdbcTemplate 放在了容器中,程序员只需自己注入即可使用。
- JdbcTemplate 的自动配置是依赖 org.springframework.boot.autoconfigure.jdbc 包下的JdbcTemplateConfiguration类。
JdbcTemplate主要提供以下几类方法:
- execute方法:可以用于执行任何SQL语句,一般用于执行DDL语句;
- update方法及batchUpdate方法:update方法用于执行新增、修改、删除等语句;batchUpdate 方法用于执行批处理相关语句;
- query方法及queryForXXX方法:用于执行查询相关语句;
- call方法:用于执行存储过程、函数相关语句。
测试案例
- 编写一个Controller,注入jdbcTemplate,编写测试方法进行访问测试;
1 | package com.github.controller; |

至此,CURD的基本操作,使用 JDBC 就搞定了。
2.整合Druid
Druid 简介
- Java程序很大一部分要操作数据库,为了提高性能操作数据库的时候,又不得不使用数据库连接池。
- Druid是阿里巴巴开源平台上一个数据库连接池实现,结合了 C3P0、DBCP 等DB池的优点,同时加入了日志监控。
- Druid可以很好的监控 DB 池连接和 SQL 的执行情况,天生就是针对监控而生的DB连接池。
- Spring Boot 2.0 以上默认使用Hikari数据源,可以说Hikari与Driud都是当前Java Web上最优秀的数据源,我们来重点介绍Spring Boot如何集成Druid数据源,如何实现数据库监控。
- Github地址:https://github.com/alibaba/druid
com.alibaba.druid.pool.DruidDataSource 基本配置参数如下:
| 配置 | 缺省值 | 说明 |
|---|---|---|
| name | 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。如果没有配置,将会生成一个名字,格式是:”DataSource-“ + System.identityHashCode(this). | |
| url | 连接数据库的url,不同数据库不一样。例如: mysql: jdbc:mysql://10.20.153.104:3306/druid2 oracle: jdbc:oracle:thin:@10.20.149.85:1521:ocnauto | |
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter。 | |
| driverClassName | 根据url自动识别 | 这一项可配可不配,如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName |
| initalSize | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时 |
| maxActive | 8 | 最大连接池数量 |
| maxIdle | 8 | ==已经不再使用,配置了也没效果== |
| minIdle | 最小连接池数量 | |
| maxWait | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 | |
| poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
| maxOpenPreparedStatements | -1 | 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 |
| validationQuery | 用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会其作用。 | |
| validationQueryTimeout | 单位:秒,检测连接是否有效的超时时间。底层调用jdbc Statement对象的void setQueryTimeout(int seconds)方法。 | |
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能 |
| testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
| timeBetweenEvictionRunsMillis | 1分钟 (1.0.14) | 有两个含义: 1) Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接 2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明。 |
| numTestsPerEvictionRun | 不再使用,一个DruidDataSource只支持一个EvictionRun | |
| numTestsPerEvictionRun | 30分钟 (1.0.14) | 连接保持空闲而不被驱逐的最长时间 |
| connectionInitSqls | 物理连接初始化的时候执行的sql | |
| exceptionSorter | 根据dbType自动识别 | 当数据库抛出一些不可恢复的异常时,抛弃连接 |
| filters | 属性类型是字符串,通过别名的方式配置扩展插件,常用 的插件有:监控统计用的filter:stat 日志用的filter:log4j 防御sql注入的filter:wall | |
| proxyFilters | 类型是List,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系 |
配置数据源
- 添加上Druid数据源依赖。
1 | <!-- https://mvnrepository.com/artifact/com.alibaba/druid --> |
- 切换数据源;之前已经说过 Spring Boot 2.0 以上默认使用com.zaxxer.hikari.HikariDataSource数据源,但可以通过spring.datasource.type指定数据源。
1 | spring: |
- 数据源切换之后,在测试类中注入DataSource,然后获取到它,输出一看便知是否成功切换;

- 切换成功!既然切换成功,就可以设置数据源连接初始化大小、最大连接数、等待时间、最小连接数 等设置项;可以查看源码。
1 | spring: |
- 导入Log4j的依赖
1 | <!-- https://mvnrepository.com/artifact/log4j/log4j --> |
- 为DruidDataSource 绑定全局配置文件中的参数,再添加到容器中,而不再使用Spring Boot的自动生成了;需要自己添加DruidDataSource组件到容器中,并绑定属性;
1 | package com.github.controller; |
- 去测试类中测试一下;看是否成功!
1 |
|
- 输出结果:可见配置参数已经生效!
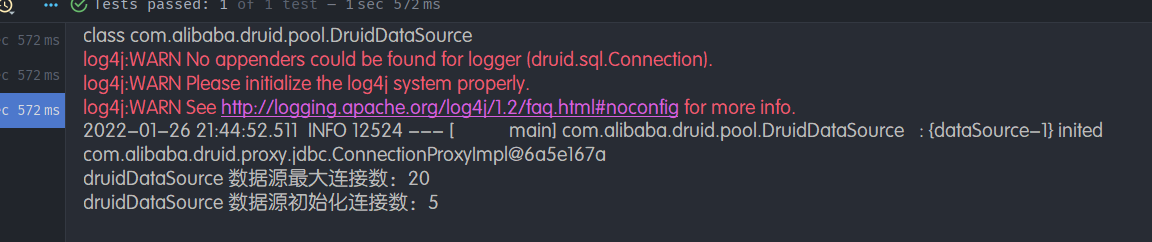
配置 Druid 数据源监控
- Druid 数据源具有监控的功能,并提供了一个web界面方便用户查看,类似安装路由器时,人家也提 供了一个默认的web页面。
- 所以第一步需要设置 Druid 的后台管理页面,比如登录账号、密码等;配置后台管理;
1 | // 配置 Druid 监控管理后台的Servlet; |
- 配置完毕后,访问: http://localhost:8080/druid/login.html
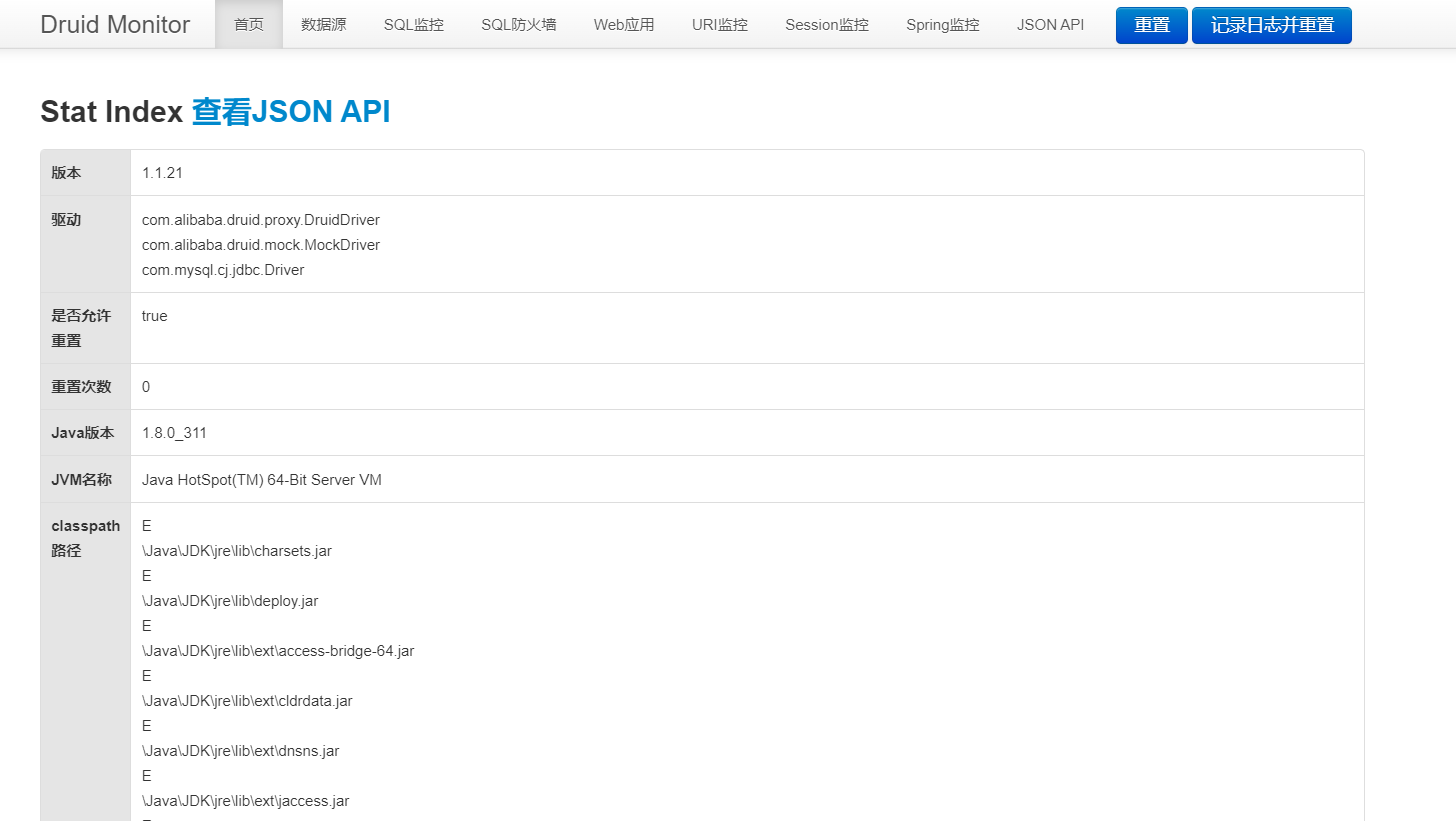
- 进入之后
- 配置Druid web监控filter过滤器
1 | // 配置 Druid 监控 之 web 监控的 filter |
平时在工作中,按需求进行配置即可,主要用作监控!
3.整合MyBatis
- 官方文档:http://mybatis.org/spring-boot-starter/mybatis-spring-boot-autoconfigure/
- Maven仓库地址:Maven Repository: org.mybatis.spring.boot » mybatis-spring-boot-starter » 2.2.1 (mvnrepository.com)
整合测试
- 导入MyBatis所需要的依赖
1 | <dependency> |
- 配置数据库连接信息
1 | spring: |
- 测试数据库是否连接成功!
1 |
|
- 创建实体类,导入
Lombok!
1 |
|
- 创建mapper目录以及对应的Mapper接口——
DepartmentMapper.java!
1 | // @Mapper: 表示本类是一个 MyBatis 的 Mapper |
- 对应的Mapper映射文件——
DepartmentMapper.xml
1 |
|
- maven配置资源过滤问题
1 | <resources> |
既然已经提供了MyBatis 的映射配置文件,自然要告诉spring boot这些文件的位置。
1 | # 指定myBatis的核心配置文件与Mapper映射文件 |
- 编写部门的DepartmentController进行测试!
1 |
|
- 启动项目访问进行测试!

增加一个员工类再测试下,为之后做准备。
- 新建一个pojo类Employee;
1 |
|
- 新建一个EmployeeMapper接口
1 | // @Mapper: 表示本类是一个 MyBatis 的 Mapper |
- 编写EmployeeMapper.xml配置文件
1 |
|
- 编写EmployeeController类进行测试。
1 |
|

测试结果完成!!!
4.SpringSecurity权限控制
1.安全简介
在 Web 开发中,安全一直是非常重要的一个方面。安全虽然属于应用的非功能性需求,但是应该在应用开发的初期就考虑进来。如果在应用开发的后期才考虑安全的问题,就可能陷入一个两难的境地:一方面,应用存在严重的安全漏洞,无法满足用户的要求,并可能造成用户的隐私数据被攻击者窃取;另一方面,应用的基本架构已经确定,要修复安全漏洞,可能需要对系统的架构做出比较重大的调整,因而需要更多的开发时间,影响应用的发布进程。因此,从应用开发的第一天就应该把安全相关的因素考虑进来,并在整个应用的开发过程中。
市面上存在比较有名的:Shiro,Spring Security !
这里需要阐述一下的是,每一个框架的出现都是为了解决某一问题而产生了,那么Spring Security框架的出现是为了解决什么问题呢?
首先我们看下它的官网介绍:Spring Security官网地址

Spring Security是一个功能强大且高度可定制的身份验证和访问控制框架。它实际上是保护基于spring的应用程序的标准。
Spring Security是一个框架,侧重于为Java应用程序提供身份验证和授权。与所有Spring项目一样,Spring安全性的真正强大之处在于它可以轻松地扩展以满足定制需求。
从官网的介绍中可以知道这是一个权限框架。想我们之前做项目是没有使用框架是怎么控制权限的?对于权限 一般会细分为功能权限,访问权限,和菜单权限。代码会写的非常的繁琐,冗余。
怎么解决之前写权限代码繁琐,冗余的问题,一些主流框架就应运而生而Spring Scecurity就是其中的一种。
Spring 是一个非常流行和成功的 Java 应用开发框架。Spring Security 基于 Spring 框架,提供了一套 Web 应用安全性的完整解决方案。一般来说,Web 应用的安全性包括用户认证(Authentication)和用户授权(Authorization)两个部分。用户认证指的是验证某个用户是否为系统中的合法主体,也就是说用户能否访问该系统。用户认证一般要求用户提供用户名和密码。系统通过校验用户名和密码来完成认证过程。用户授权指的是验证某个用户是否有权限执行某个操作。在一个系统中,不同用户所具有的权限是不同的。比如对一个文件来说,有的用户只能进行读取,而有的用户可以进行修改。一般来说,系统会为不同的用户分配不同的角色,而每个角色则对应一系列的权限。
对于上面提到的两种应用情景,Spring Security 框架都有很好的支持。在用户认证方面,Spring Security 框架支持主流的认证方式,包括 HTTP 基本认证、HTTP 表单验证、HTTP 摘要认证、OpenID 和 LDAP 等。在用户授权方面,Spring Security 提供了基于角色的访问控制和访问控制列表(Access Control List,ACL),可以对应用中的领域对象进行细粒度的控制。
2.实战测试
1.实验环境搭建
- 新建一个初始的springboot项目web模块,thymeleaf模块
1 | <!--thymeleaf--> |
- 导入静态资源
1 | welcome.html |
- controller跳转!
1 | package com.github.controller; |
- 测试实验环境是否OK!
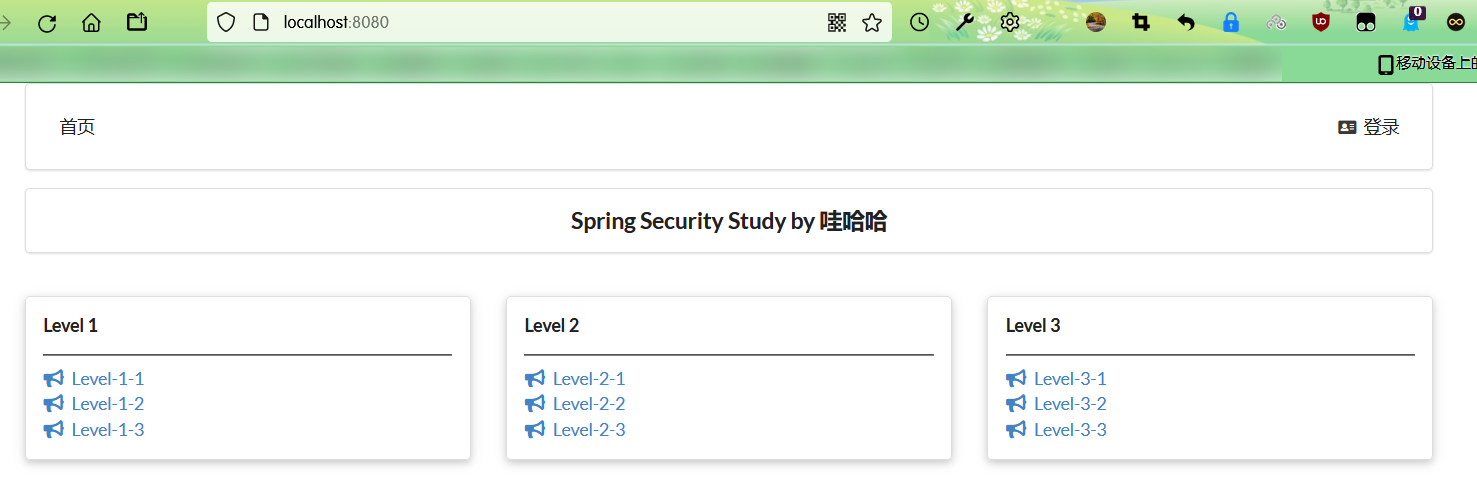
2.认识SpringSecurity
Spring Security 是针对Spring项目的安全框架,也是Spring Boot底层安全模块默认的技术选型,他可以实现强大的Web安全控制,对于安全控制,我们仅需要引入 spring-boot-starter-security 模块,进行少量的配置,即可实现强大的安全管理!
记住几个类:
- WebSecurityConfigurerAdapter:自定义Security策略
- AuthenticationManagerBuilder:自定义认证策略
- @EnableWebSecurity:开启WebSecurity模式
Spring Security的两个主要目标是 “认证” 和 “授权”(访问控制)。
“认证”(Authentication)
身份验证是关于验证您的凭据,如用户名/用户ID和密码,以验证您的身份。
身份验证通常通过用户名和密码完成,有时与身份验证因素结合使用。
“授权” (Authorization)
授权发生在系统成功验证您的身份后,最终会授予您访问资源(如信息,文件,数据库,资金,位置,几乎任何内容)的完全权限。
这个概念是通用的,而不是只在Spring Security 中存在。
3.认证和授权
目前,我们的测试环境,是谁都可以访问的,只要使用 Spring Security 增加上认证和授权的功能。
- 引入 Spring Security 模块
1 | <dependency> |
- 编写 Spring Security 配置类
查看个人项目中的版本,找到对应的帮助文档:Spring Security Reference
- 编写基础配置类
1 | package com.github.config; |
- 定制请求的授权规则
1 |
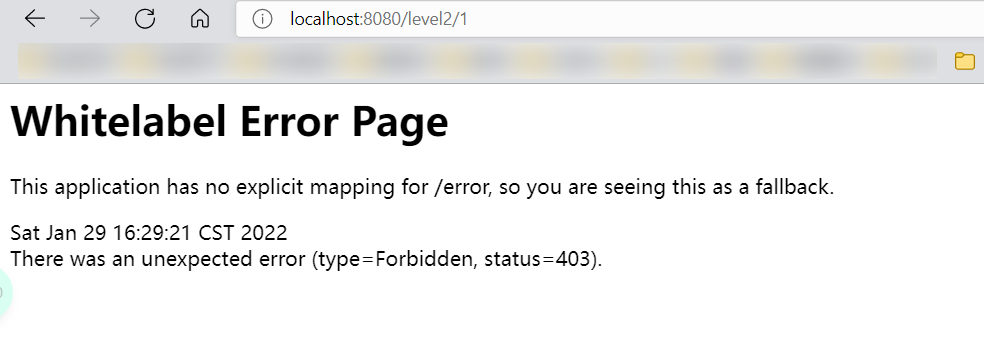
|
- 测试一下:发现除了首页都进不去了!因为目前没有登录的角色,因为请求需要登录的角色拥有对应的权限才可以!
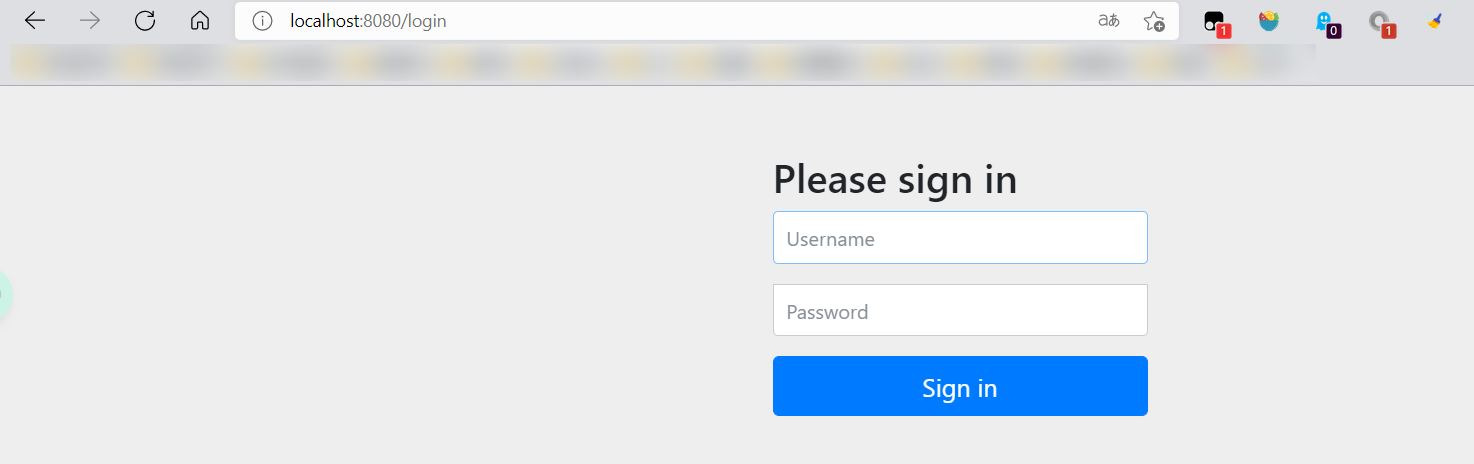
- 在configure()方法中加入以下配置,开启自动配置的登录功能!
1 | // 开启自动配置的登录功能 |
- 测试一下:发现,没有权限的时候,会跳转到登录的页面!
- 查看刚才登录页的注释信息;
- 可以定义认证规则,重写configure(AuthenticationManagerBuilder auth)方法。
1 | // 定义认证规则 |
- 测试,使用这些账号登录进行测试!发现会报错!
- 原因:要将前端传过来的密码进行某种方式加密,否则就无法登录,修改代码。
1 | // 定义认证规则 |
- 测试,发现,登录成功,并且==每个角色只能访问自己认证下的规则==!

4.权限控制和注销
图标库网站:https://semantic-ui.com/

- 开启自动配置的注销的功能
1 | // 定制请求的授权规则 |
- 在前端,增加一个注销的按钮,index.html 导航栏中。
1 | <a class="item" th:href="@{/logout}"> |
- 去测试一下,登录成功后点击注销,发现注销完毕会跳转到登录页面!
- 但是,当我们想让他注销成功后,依旧可以跳转到首页,该怎么处理呢?
1 | // .logoutSuccessUrl("/"); 注销成功来到首页 |
- 测试,注销完毕后,发现跳转到首页,OK!

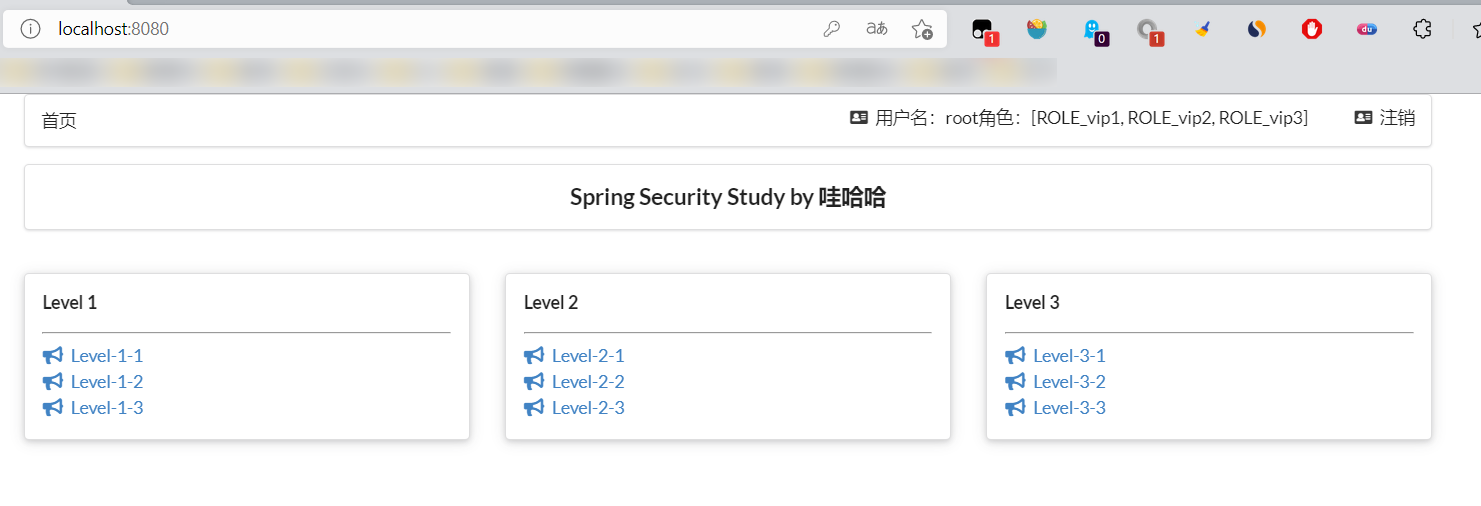
- 现在又来一个需求:用户没有登录的时候,导航栏上只显示登录按钮,用户登录之后,导航栏可以显示登录的用户信息及注销按钮!还有就是,比如test这个用户,它只有 vip2,vip3功能,那么登录则只显示这两个功能,而vip1的功能菜单不显示!这个就是真实的网站情况了!该如何做呢?
需要结合thymeleaf中的一些功能
sec:authorize=”isAuthenticated()”:是否认证登录!来显示不同的页面。
Maven依赖:
1 | <!-- https://mvnrepository.com/artifact/org.thymeleaf.extras/thymeleaf-extras-springsecurity4 --> |
- 修改前端页面
- 导入命名空间
1 | <!-- https://mvnrepository.com/artifact/org.thymeleaf.extras/thymeleaf-extras-springsecurity4 --> |
- 修改导航栏,增加认证判断
1 | <!--登录注销--> |
- 重启测试,可以登录试试看,登录成功后确实,显示了我们想要的页面;
- 如果注销404了,就是因为它默认防止csrf跨站请求伪造,因为会产生安全问题,可以将请求改为post表单提交,或者在spring security中关闭csrf功能;还可以试试:在配置中增加
http.csrf().disable();
1 | http.csrf().disable(); // 关闭csrf功能:跨站请求伪造,默认只能通过post方式提交logout请求 |
- 继续将下面的角色功能块认证完成!
1 | <!-- sec:authorize="hasRole('vip1')" --> |
- 测试一下!
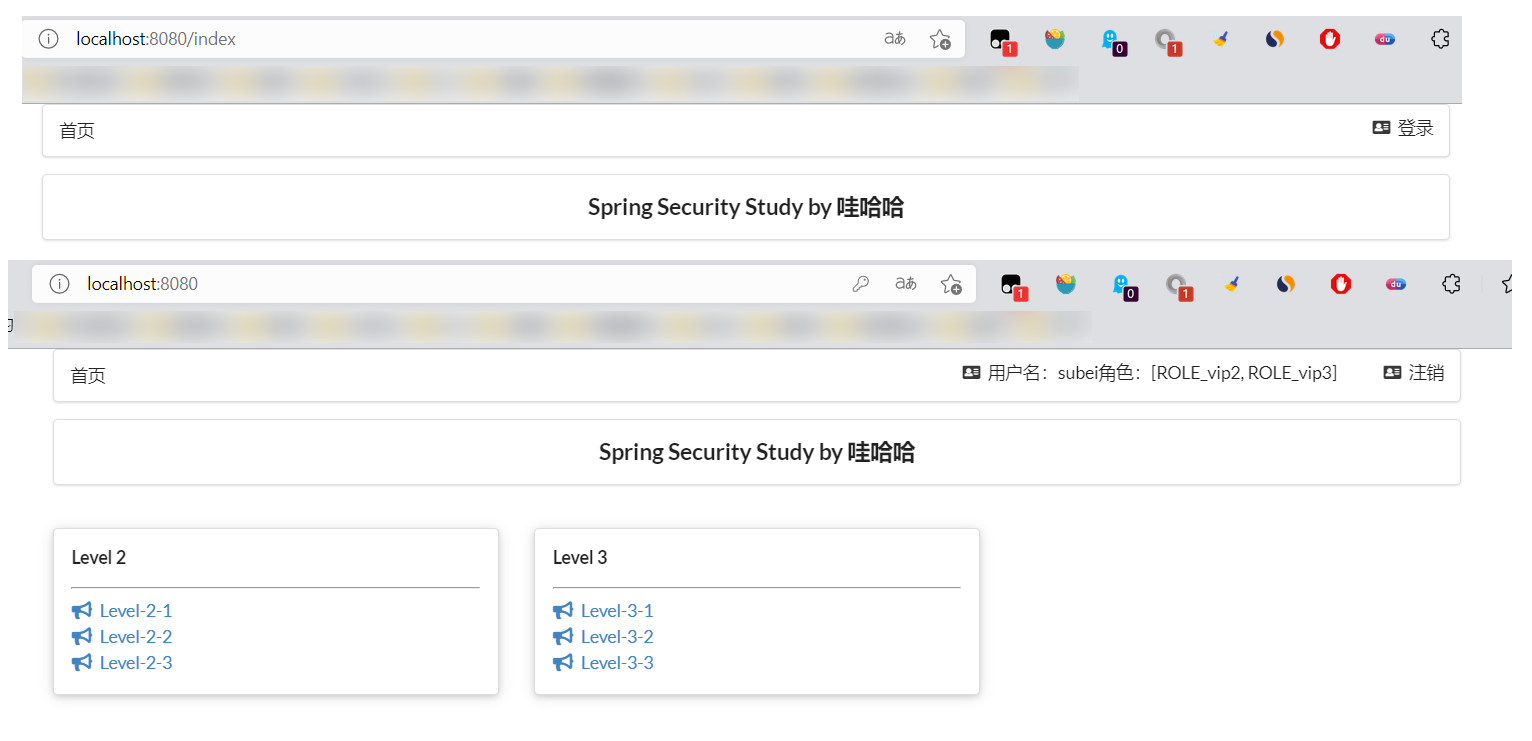
权限控制和注销搞定!
5.记住我
现在的情况:只要登录之后,关闭浏览器,再登录,就会让我们重新登录,但是很多网站的情况,就是有一个记住密码的功能,这个该如何实现呢?很简单
- 开启记住我功能
1 | // 定制请求的授权规则 |
- 再次启动项目测试一下,发现登录页多了一个记住我功能,登录之后关闭浏览器,然后重新打开浏览器访问,发现用户依旧存在!
思考:如何实现的呢?其实非常简单
- 可以查看浏览器的cookie

- 点击注销的时候,可以发现,spring security 帮我们自动删除了这个cookie。
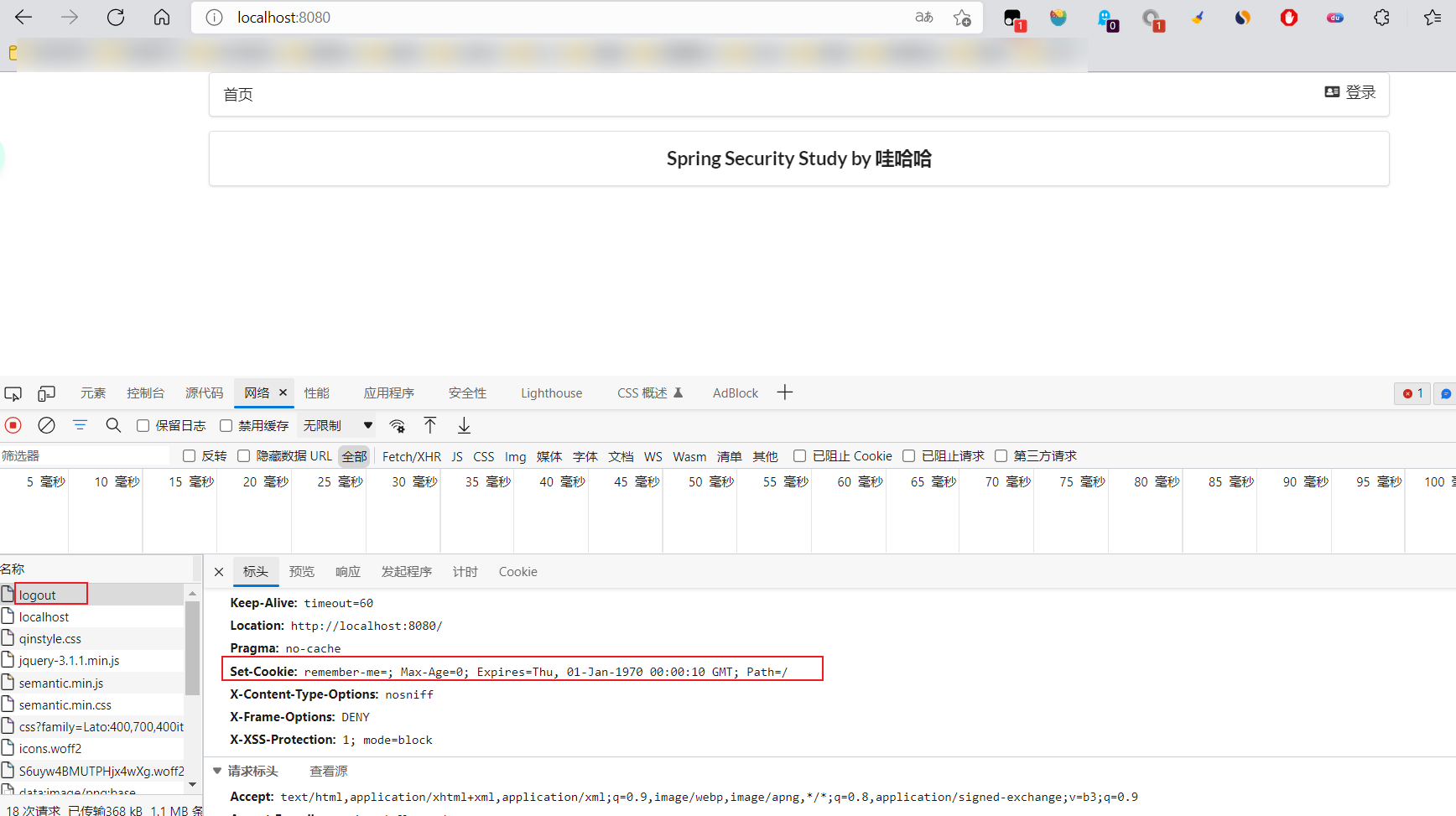
- 结论:登录成功后,将cookie发送给浏览器保存,以后登录带上这个cookie,只要通过检查就可以免登录了。如果点击注销,则会删除这个cookie,具体的原理参考JavaWeb阶段!
6.定制登录页
现在这个登录页面都是spring security 默认的,怎么样可以使用自己写的Login界面呢?
- 在刚才的登录页配置后面指定 loginpage
1 | http.formLogin().loginPage("/toLogin"); |
- 然后前端也需要指向我们自己定义的 login请求
1 | <a class="item" th:href="@{/toLogin}"> |
- 要登录,则需要将这些信息发送到哪里,我们也需要配置,login.html 配置提交请求及方式,方式必须为post:
- 在 loginPage()源码中的注释上有写明:

1 | <form th:action="@{/login}" method="post"> |
4、这个请求提交上来,我们还需要验证处理,怎么做呢?我们可以查看formLogin()方法的源码!我们配置接收登录的用户名和密码的参数!
1 | http.formLogin() |
5、在登录页增加记住我的多选框
1 | <input type="checkbox" name="remember"> 记住我 |
6、后端验证处理!
1 | //定制记住我的参数! |
- 测试,OK
完整配置代码
1 | package com.github.config; |
5.整合Shiro
1.Shiro简介
1.什么是Shiro?
- Apache Shiro 是一个Java 的安全(权限)框架。
- Shiro 可以非常容易的开发出足够好的应用,其不仅可以用在JavaSE环境,也可以用在Java EE环
境。 - Shiro可以完成,认证,授权,加密,会话管理,Web集成,缓存等。
- 下载地址:http://shiro.apache.org/
2.有哪些功能?
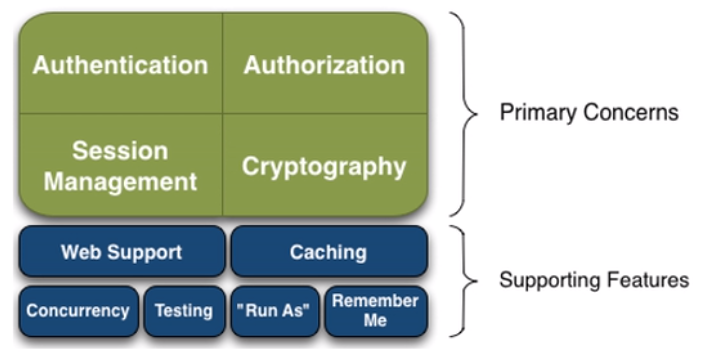
- Authentication:身份认证、登录,验证用户是不是拥有相应的身份;
- Authorization:授权,即权限验证,验证某个已认证的用户是否拥有某个权限,即判断用户能否进行什么操作,如:验证某个用户是否拥有某个角色,或者细粒度的验证某个用户对某个资源是否具有某个权限!
- Session Manager:会话管理,即用户登录后就是第一次会话,在没有退出之前,它的所有信息都在会话中;会话可以是普通的JavaSE环境,也可以是Web环境;
- Cryptography:加密,保护数据的安全性,如密码加密存储到数据库中,而不是明文存储;
- Web Support:Web支持,可以非常容易的集成到Web环境;
- Caching:缓存,比如用户登录后,其用户信息,拥有的角色、权限不必每次去查,这样可以提高效率
- Concurrency:Shiro支持多线程应用的并发验证,即,如在一个线程中开启另一个线程,能把权限自动的传播过去
- Testing:提供测试支持;
- Run As:允许一个用户假装为另一个用户(如果他们允许)的身份进行访问;
- Remember Me:记住我,这个是非常常见的功能,即一次登录后,下次再来的话不用登录了。
3.Shiro架构(外部)
- 从外部来看Shiro,即从应用程序角度来观察如何使用shiro完成工作:
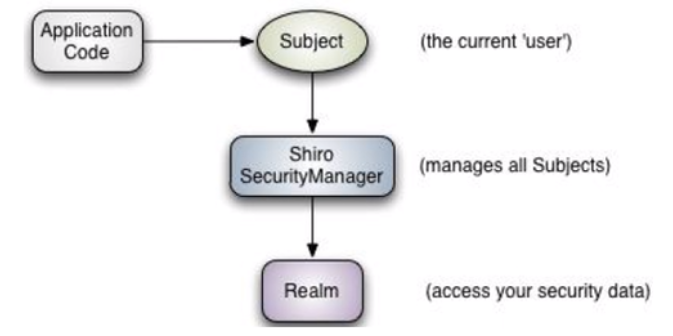
- subject: 应用代码直接交互的对象是Subject,也就是说Shiro的对外API核心就是Subject, Subject代表了当前的用户,这个用户不一定是一个具体的人,与当前应用交互的任何东西都是 Subject,如网络爬虫,机器人等,与Subject的所有交互都会委托给SecurityManager;Subject其 实是一个门面,SecurityManageer 才是实际的执行者
- SecurityManager:安全管理器,即所有与安全有关的操作都会与SercurityManager交互,并且它 管理着所有的Subject,可以看出它是Shiro的核心,它负责与Shiro的其他组件进行交互,它相当于 SpringMVC的DispatcherServlet的角色
- Realm:Shiro从Realm获取安全数据(如用户,角色,权限),就是说SecurityManager 要验证 用户身份,那么它需要从Realm 获取相应的用户进行比较,来确定用户的身份是否合法;也需要从 Realm得到用户相应的角色、权限,进行验证用户的操作是否能够进行,可以把Realm看成 DataSource;
4.Shiro架构(内部)
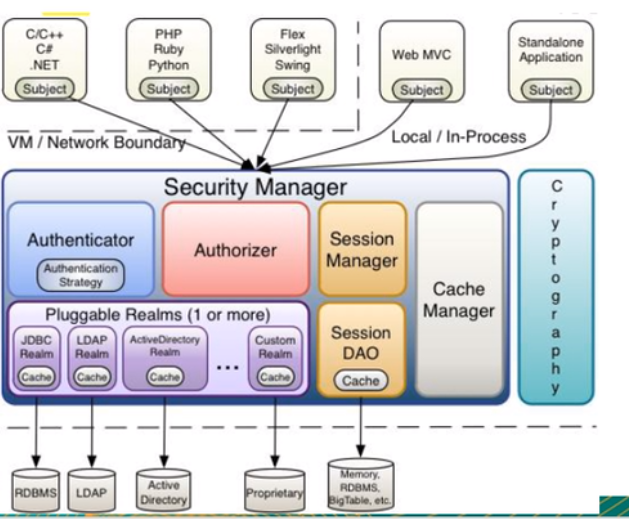
- Subject:任何可以与应用交互的 ‘用户’;
- Security Manager:相当于SpringMVC中的DispatcherServlet;是Shiro的心脏,所有具体的交互 都通过Security Manager进行控制,它管理者所有的Subject,且负责进行认证,授权,会话,及缓存的管理。
- Authenticator:负责Subject认证,是一个扩展点,可以自定义实现;可以使用认证策略(Authentication Strategy),即什么情况下算用户认证通过了;
- Authorizer:授权器,即访问控制器,用来决定主体是否有权限进行相应的操作;即控制着用户能访问应用中的那些功能;
- Realm:可以有一个或者多个的realm,可以认为是安全实体数据源,即用于获取安全实体的,可以用JDBC实现,也可以是内存实现等等,由用户提供;所以一般在应用中都需要实现自己的realm。
- SessionManager:管理Session生命周期的组件,而Shiro并不仅仅可以用在Web环境,也可以用在普通的JavaSE环境中。
- CacheManager:缓存控制器,来管理如用户,角色,权限等缓存的;因为这些数据基本上很少改变,放到缓存中后可以提高访问的性能;
- Cryptography:密码模块,Shiro 提高了一些常见的加密组件用于密码加密,解密等。
2.Hello,Shiro
- 查看官网文档:http://shiro.apache.org/tutorial.html
- 官方的quickstart:https://github.com/apache/shiro/tree/master/samples/quickstart/
1.快速实践
- 创建一个
maven父工程,用于学习Shiro,删掉不必要的东西。 - 创建一个普通的Maven子工程:shiro-01-helloworld。
- 根据官方文档,导入Shiro的依赖。
1 | <dependencies> |
- 编写Shiro配置——log4j.properties。
1 | log4j.rootLogger=INFO, stdout |
- shiro.ini
1 | [users] |
- 编写自己的QuickStrat
1 | /* |
测试运行一下。
发现,执行完毕什么都没有,可能是maven依赖中的作用域问题,我们需要将scope作用域删掉,
默认是在test,然后重启,那么我们的quickstart就结束了,默认的日志消息!
1 | [main] INFO [org.apache.shiro.session.mgt.AbstractValidatingSessionManager] - Enabling session validation scheduler... |
- OK!
2.代码解释
- 导入了一堆包!
- 类的描述
1 | /** |
- 通过工厂模式创建SecurityManager的实例对象。
1 | // The easiest way to create a Shiro SecurityManager with configured |
- 获取当前的Subject
1 | // get the currently executing user: 获取当前正在执行的用户 |
- session的操作
1 | // 用会话做一些事情(不需要web或EJB容器!!!) |
- 用户认证功能
1 | // 测试当前的用户是否已经被认证,即是否已经登录! |
- 角色检查
1 | // test a role: |
- 权限检查,粗粒度
1 | //测试用户是否具有某一个权限,行为 |
- 权限检查,细粒度
1 | //测试用户是否具有某一个权限,行为,比上面更加的具体! |
- 注销操作
1 | //执行注销操作! |
- 退出系统
System.exit(0);
OK,一个简单的Shiro程序体验结束!!!
3.集成shiro
1.准备工作
- 搭建一个SpringBoot项目、选中web模块即可!
- 导入Maven依赖
thymeleaf
1 | <!--thymeleaf模板--> |
- 编写一个页面 index.html——
templates📂
1 |
|
- 编写controller进行访问测试。
1 | package com.github.controller; |
- 访问测试!
2.整合Shiro
回顾核心API:
- Subject:用户主体
- SecurityManager:安全管理器
- Realm:Shiro 连接数据
步骤:
- 导入Shiro 和 spring整合的依赖。
1 | <dependency> |
- 编写Shiro 配置类——
config包
1 | package com.github.config; |
- 创建一个realm对象,需要自定义一个realm的类,用来编写一些查询的方法,或者认证与授权的逻辑。
1 | package com.github.config; |
- 将这个类注册到我们的Bean中!——
ShiroConfig
1 |
|
- 创建
DefaultWebSecurityManager
1 | // 创建 DefaultWebSecurityManager |
- 创建
ShiroFilterFactoryBean
1 | // 创建 ShiroFilterFactoryBean |
完整的配置:
1 | package com.github.config; |
3.页面拦截实现
- 编写两个页面、在templates目录下新建一个user目录
add.html、update.html
1 |
|
1 |
|
- 编写跳转到页面的controller
1 |
|
- 在index页面上,增加跳转链接
1 | <body> |
- 测试页面跳转是否OK
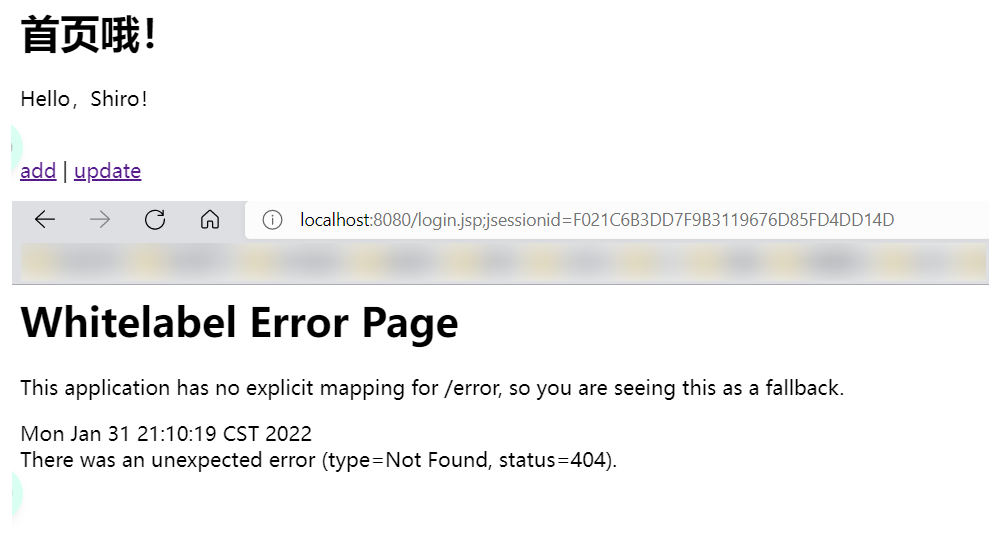
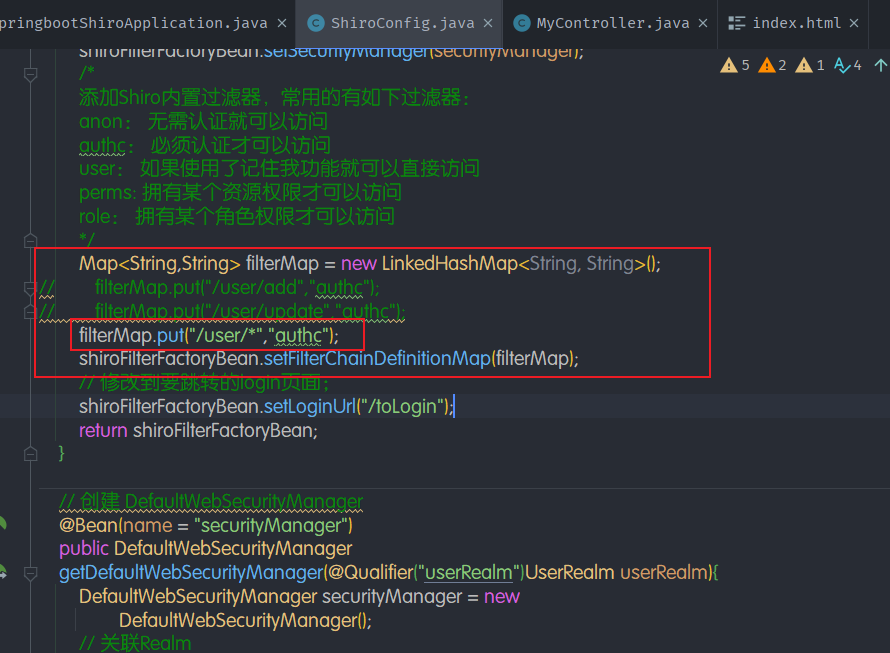
- 准备添加Shiro的内置过滤器
1 | // 创建 ShiroFilterFactoryBean |
- 再起启动测试,访问链接进行测试!拦截OK!但是发现,点击后会跳转到一个Login.jsp页面,这 个不是我们想要的效果,我们需要自己定义一个Login页面!
- 编写一个个人的Login.html页面
1 |
|
- 编写跳转的controller
1 |
|
- 在shiro中配置一下!
ShiroFilterFactoryBean() 方法下面
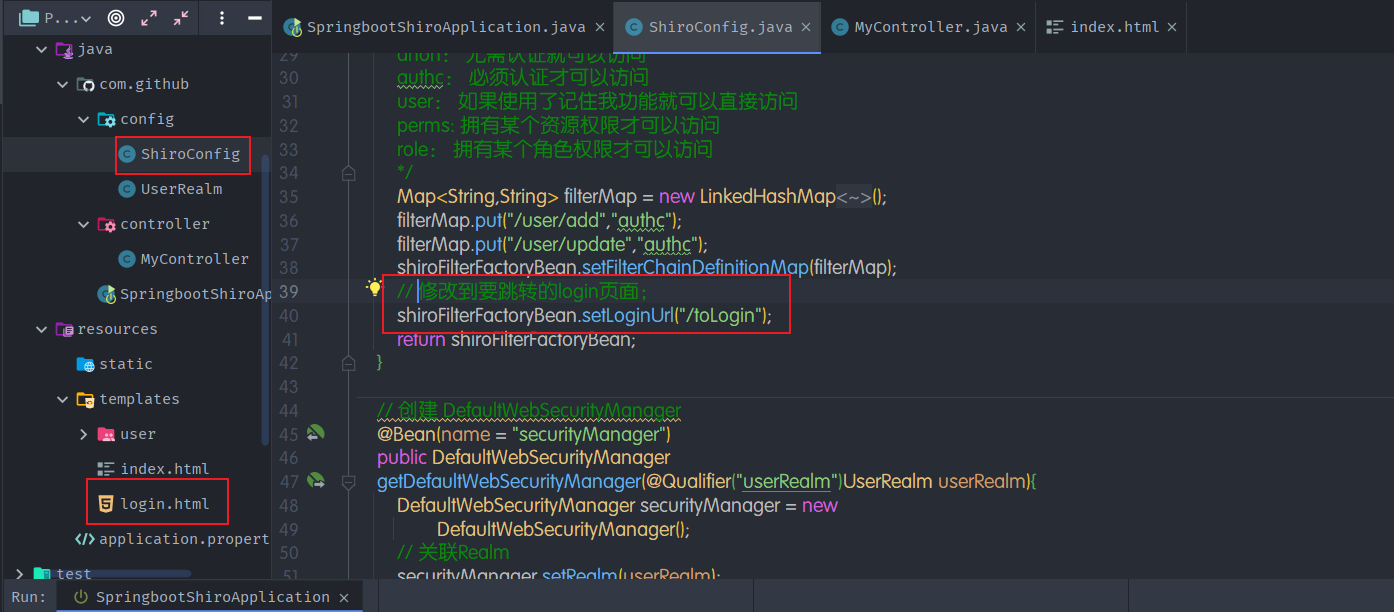
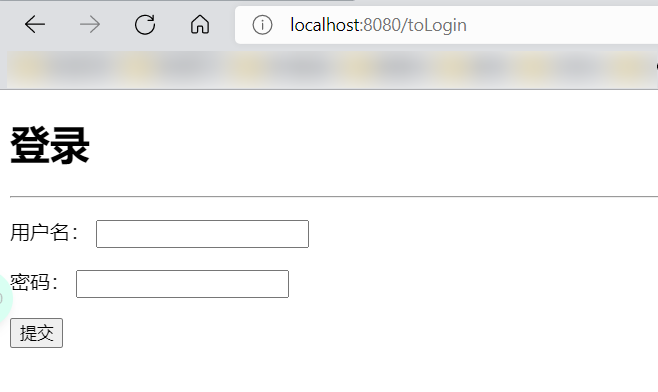
- 再次测试,成功的跳转到了我们指定的Login页面!
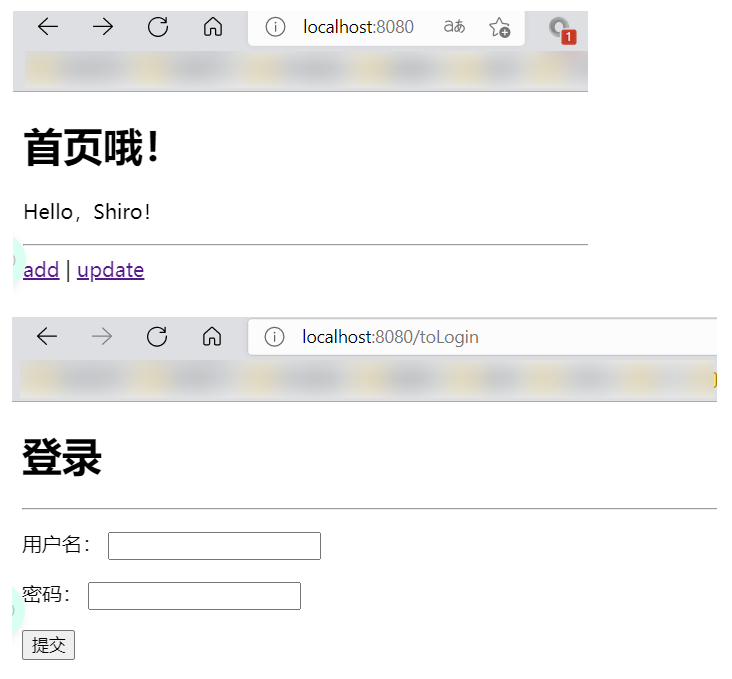
- 优化一下,使用通配符来操作!
- 测试一下!
4.登录认证操作
- 编写登录的controller
1 | // 登陆操作 |
- 在前端修改对应的信息输出或者请求!登录页面增加一个msg提示:
1 | <p style="color:red;" th:text="${msg}"></p> |
- 给表单增加一个提交地址:
1 | <form th:action="@{/login}"> |
- 测试一下:
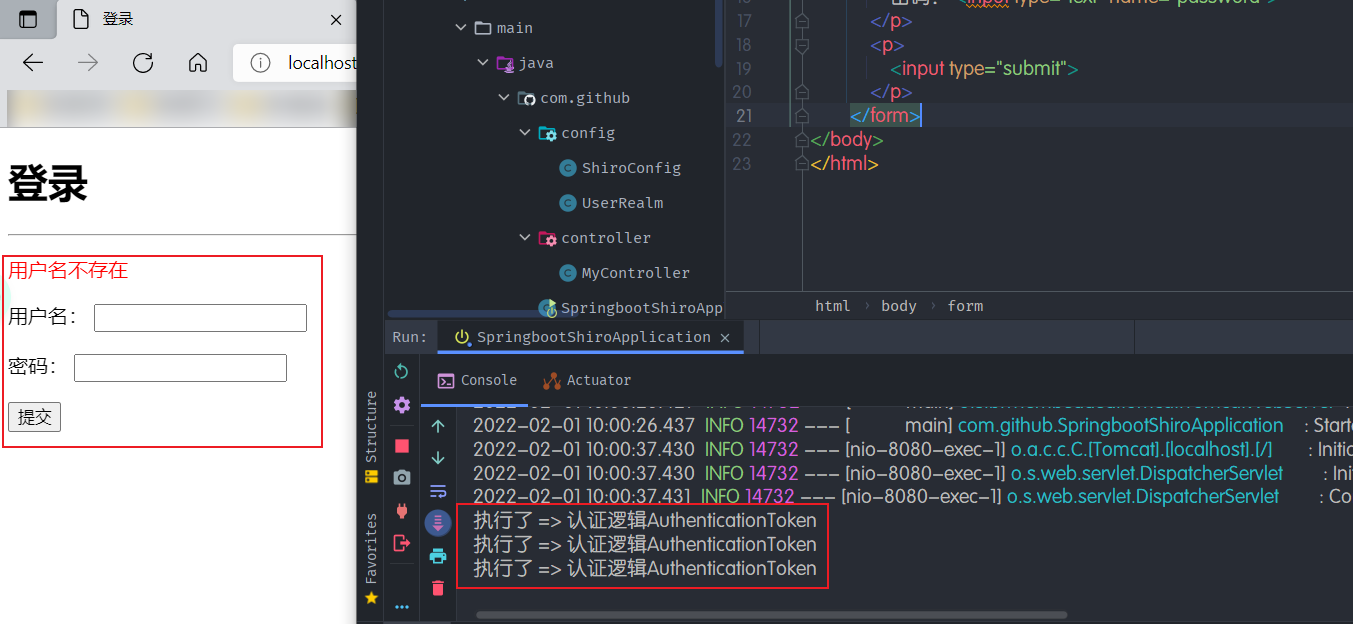
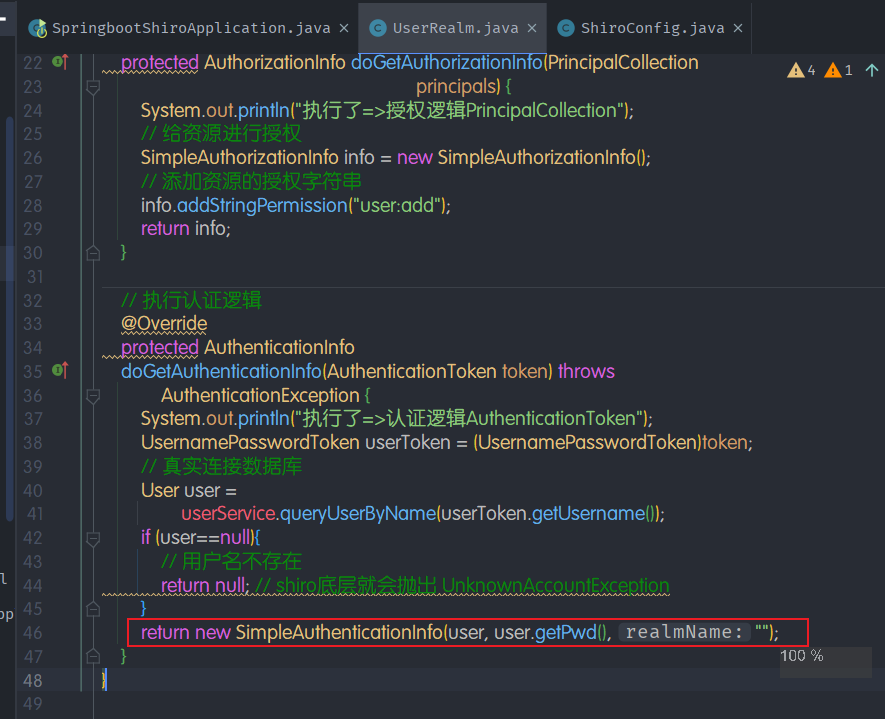
- 在UserRealm中编写用户认证的判断逻辑:
1 | // 执行认证逻辑 |
- 测试一下!
5.整合数据库
1 | CREATE DATABASE `mybatis`; |
- 导入Mybatis相关依赖
1 | <!-- 引入 myBatis,这是 MyBatis官方提供的适配 Spring Boot 的,而不是Spring |
- 编写配置文件-连接配置——
application.yml
1 | spring: |
- 编写mybatis的配置——
application.properties
1 | # 别名配置 |
- 编写实体类,引入Lombok
1 | <dependency> |
1 |
|
- 编写Mapper接口
1 |
|
- 编写Mapper配置文件
1 |
|
- 编写UserService 层
1 | public interface UserService { |
1 |
|
- 测试一下,保证能够从数据库中查询出来。
1 |
|

- 改造UserRealm,连接到数据库进行真实的操作!
1 | // 自定义Realm |
- 测试成功!
思考:密码比对原理探究
- 这个Shiro,是怎么帮我们实现密码自动比对的呢?
- 去 realm的父类
AuthorizingRealm的父类AuthenticatingRealm中找一个方法; - 核心:
getCredentialsMatcher() 翻译过来:获取证书匹配器; - 去看这个接口
CredentialsMatcher有很多的实现类,MD5盐值加密;
- 去 realm的父类
密码一般都不能使用明文保存?
- 需要加密处理;思路分析
- 如何把一个字符串加密为MD5;
- 替换当前的Realm 的 CredentialsMatcher 属性,直接使用
Md5CredentialsMatcher对象, 并设置加密算法;
1 | // 密码验证 |
6.用户授权操作
使用shiro的过滤器来拦截请求即可!
- 在
ShiroFilterFactoryBean中添加一个过滤器:
1 | // 授权过滤器 |
- 再次启动测试一下,访问add,发现以下错误!未授权错误!
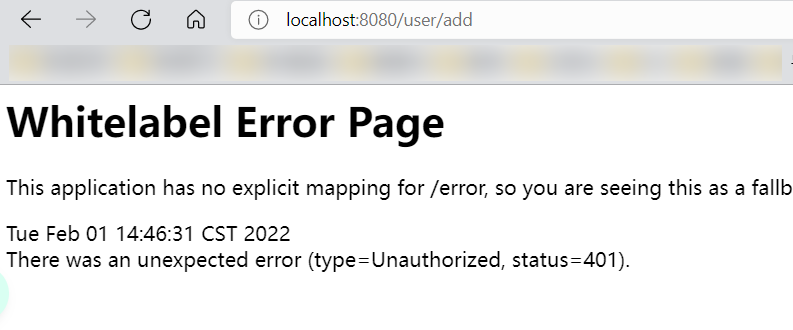
- 注意:当我们实现权限拦截后,shiro会自动跳转到未授权的页面,但没有这个页面,所有401了;
- 配置一个未授权的提示的页面,增加一个controller提示;
1 |
|
- 然后再 shiroFilterFactoryBean 中配置一个未授权的请求页面!
1 | shiroFilterFactoryBean.setUnauthorizedUrl("/noauth"); |
- 测试,现在没有授权,可以跳转到我们指定的位置了!
7.用户授权操作
- 在UserRealm 中添加授权的逻辑,增加授权的字符串!
1 | // 执行授权逻辑 |
- 再次登录测试,发现登录的用户是可以进行访问add 页面了!授权成功!
问题,我们现在完全是硬编码,无论是谁登录上来,都可以实现授权通过,但是真实的业务情况应该 是,每个用户拥有自己的一些权限,从而进行操作,所以说,权限,应该在用户的数据库中,正常的情 况下,应该数据库中是由一个权限表的,我们需要联表查询,但是这里为了大家操作理解方便一些,我 们直接在数据库表中增加一个字段来进行操作!

- 修改实体类,增加一个字段
1 |
|
在自定义的授权认证中,获取登录的用户,从而实现动态认证授权操作!
在用户登录授权的时候,将用户放在 Principal 中,改造下之前的代码
1
return new SimpleAuthenticationInfo(user, user.getPwd(), "");
- 然后再授权的地方获得这个用户,从而获得它的权限
1 | // 执行授权逻辑 |
- 给数据库中的用户增加一些权限

- 在过滤器中,将update请求也进行权限拦截下
1 |
- 启动测试,登录不同的账户,进行测试一下!测试完美通过OK!
8.整合Thymeleaf
根据权限展示不同的前端页面
- 添加Maven的依赖;
1 | <!--https://mvnrepository.com/artifact/com.github.theborakompanioni/thymeleaf-extras-shiro --> |
- 配置一个shiro的Dialect ,在shiro的配置中增加一个Bean
1 | // 配置ShiroDialect:方言,用于 thymeleaf 和 shiro 标签配合使用 |
- 修改前端的配置
1 |
|
- 测试一下,可以发现,现在首页什么都没有了,因为我们没有登录,我们可以尝试登录下,来判断这个Shiro的效果!登录后,可以看到不同的用户,有不同的效果,现在就已经接近完美了~!但还有问题!
- 在用户登录后应该把信息放到Session中,我们完善下!在执行==认证逻辑==时候,加入session。
1 | Subject subject = SecurityUtils.getSubject(); |
- 前端从session中获取,然后用来判断是否显示登录。
1 | <p th:if="${session.loginUser==null}"> |
- 测试一下!

6.集成Swagger

1.Swagger简介
前后端分离
- 前端 -> 前端控制层、视图层;
- 后端 -> 后端控制层、服务层、数据访问层;
- 前后端通过API进行交互;
- 前后端相对独立且松耦合。
产生的问题
- 前后端集成,前端或者后端无法做到“及时协商,尽早解决”,最终导致问题集中爆发。
解决方案
- 首先定义schema[计划的提纲],并实时跟踪最新的API,降低集成风险。
- 早些年:指定word计划文档;
- 前后端分离:
- 前端测试后端接口:postman
- 后端提供接口,需要实时更新最新的消息及改动!
Swagger
- 号称世界上最流行的API框架;
- Restful API文档在线自动生成器 => API 文档 与API 定义同步更新。
- 直接运行,在线测试API;
- 支持多种语言(如:Java,PHP等);
- 官网:https://swagger.io/
2.SpringBoot集成Swagger
SpringBoot集成Swagger => springfox,两个jar包
- Springfox -> swagger2;
- swagger -> springmvc。
使用Swagger
- 要求:JDK1.8 + 否则swagger2无法运行。
步骤:
新建一个SpringBoot-web项目

添加Maven依赖
1 | <!-- https://mvnrepository.com/artifact/io.springfox/springfox-swagger2 --> |
- 编写HelloController,测试确保运行成功!
1 |
|
- 要使用Swagger,我们需要编写一个配置类-SwaggerConfig来配置 Swagger
1 | // 配置类 |
- ==由于spring boot版本问题,如果启动项目报错空指针异常,将spring boot降级为2.5.5版本即可==。访问测试:http://localhost:8080/swagger-ui.html,可以看到swagger的界面。
- 注:
3.0的jar访问不了,降级2.9.2就可以了。
3.配置Swagger
- Swagger实例Bean是Docket,所以通过配置Docket实例来配置Swaggger。
1 |
|
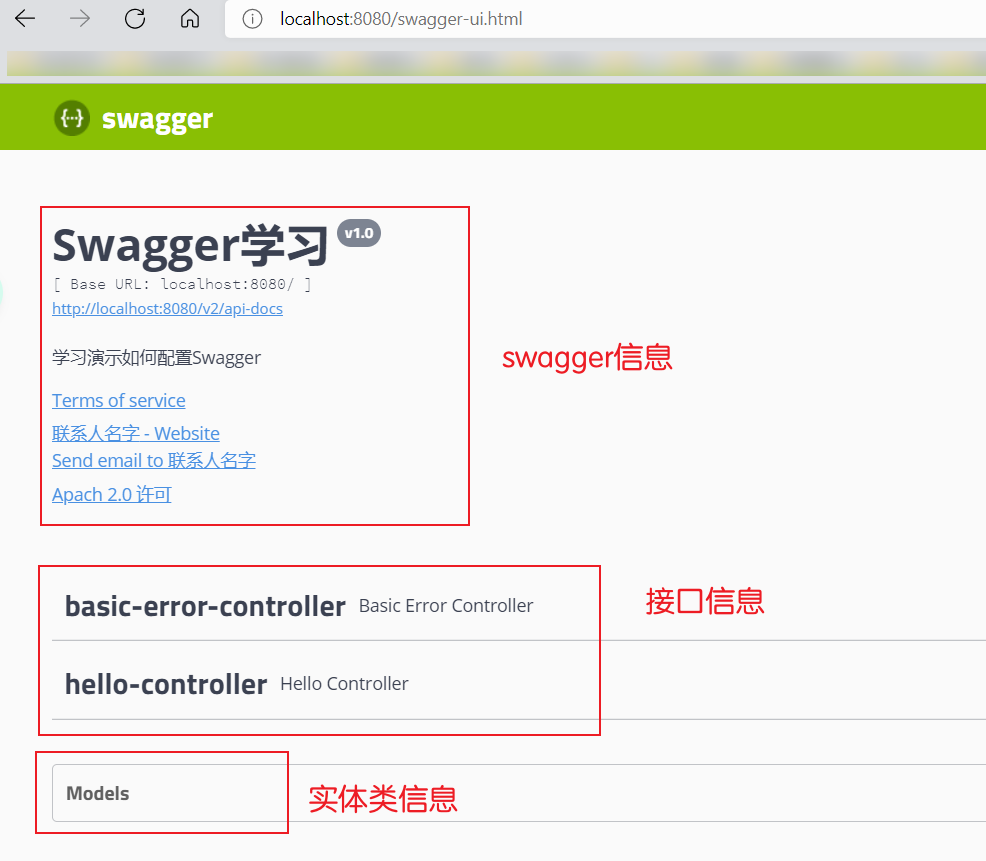
- 可以通过apiInfo()属性配置文档信息;
1 | // 配置文档信息 |
- Docket实例关联上apiInfo()
1 |
|
- 重启项目,访问测试 http://localhost:8080/swagger-ui.html 效果如下:
4.配置扫描端口
- 构建Docket时通过select()方法配置怎么扫描接口。
1 |
|
重启项目测试,由于我们配置根据包的路径扫描接口,所以只能看到一个类!!!
除了通过包路径配置扫描接口外,还可以通过配置其他方式扫描接口,这里注释一下所有的配置方 式:
1 | any() // 扫描所有,项目中的所有接口都会被扫描到 |
- 除此之外,还可以配置接口扫描过滤:
1 |
|

- 可选值还有:
1 | regex(final String pathRegex) // 通过正则表达式控制 |
5.配置Swagger开关
- 通过enable()方法配置是否启用swagger,如果是false,swagger将不能在浏览器中访问了。
1 |
|
- 如何动态配置当项目处于test、dev环境时显示swagger,处于prod时不显示?
- 在配置文件配置swaggerFlag的值,在dev、prod、stag的配置文件中配置,然后在swaggerConfig里面获取这个值,这样不管环境怎么变都不影响代码!
1 |
|
- 在项目中增加一个dev的配置文件查看效果!
6.配置API分组
- 如果没有配置分组,默认是default。通过groupName()方法即可配置分组:
1 |
|
- 重启项目查看分组

- 如何配置多个分组?配置多个分组只需要配置多个docket即可:
1 |
|
- 重启项目查看。
7.实体配置
- 新建一个实体类
1 |
|
- 只要这个实体在请求接口的返回值上(即使是泛型),都能映射到实体项中:
1 | // controller文件中…… |
- 重启查看测试:
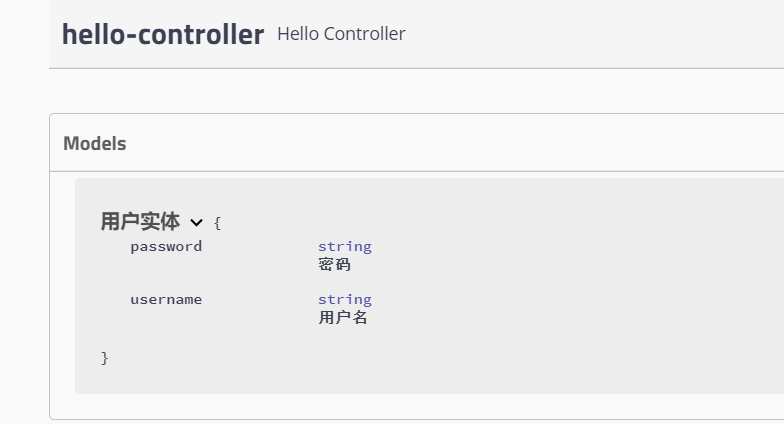
注:并不是因为@ApiModel这个注解让实体显示在这里了,而是只要出现在接口方法的返回值上的实体都会显示在这里,而@ApiModel和@ApiModelProperty这两个注解只是为实体添加注释的。
@ApiModel为类添加注释;
@ApiModelProperty为类属性添加注释;
8.常用注解
Swagger的所有注解定义在io.swagger.annotations包下!
- 下面列一些经常用到的,未列举出来的可以另行查阅说明:
| Swagger注解 | 简单说明 |
|---|---|
| @Api(tags = “xxx模块说明”) | 作用在模块类上 |
| @ApiOperation(“xxx接口说明”) | 作用在接口方法上 |
| @ApiModel(“xxxPOJO说明”) | 作用在模型类上:如VO、BO |
| @ApiModelProperty(value = “xxx属性说明”,hidden = true) | 作用在类方法和属性上,hidden设置为true可以隐藏该属性 |
| @ApiParam(“xxx参数说明”) | 作用在参数、方法和字段上,类似@ApiModelProperty |
- 也可以给请求的接口配置一些注释:
1 | // Operation接口,不是放在类上的,是方法 |
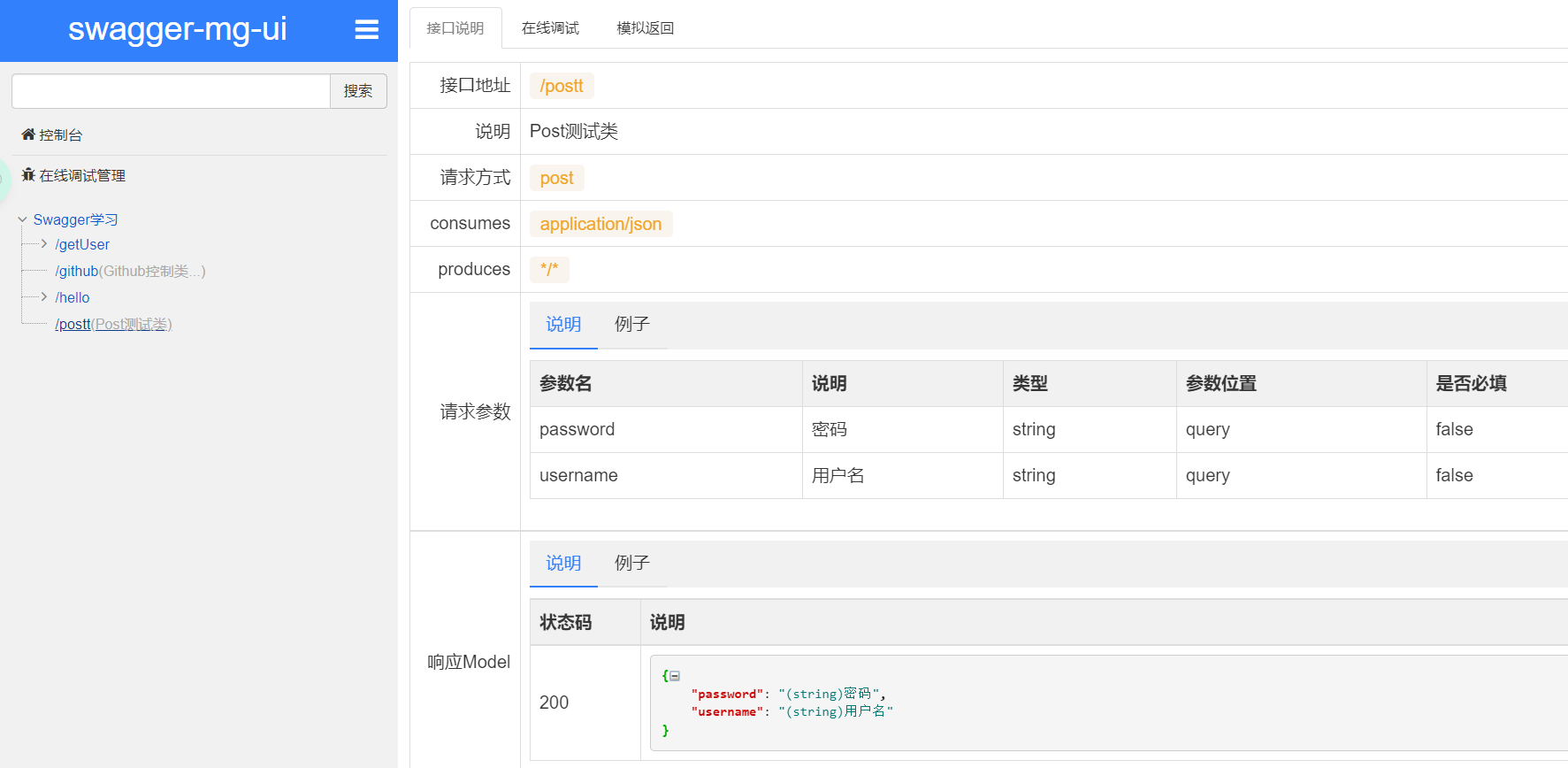
这样的话,可以给一些比较难理解的属性或者接口,增加一些配置信息,让人更容易阅读!
相较于传统的Postman或Curl方式测试接口,使用swagger简直就是傻瓜式操作,不需要额外说明文档(写得好本身就是文档)而且更不容易出错,只需要录入数据然后点击Execute,如果再配合自动化框架,可以说基本就不需要人为操作了。
Swagger是个优秀的工具,现在国内已经有很多的中小型互联网公司都在使用它,相较于传统的要先出Word接口文档再测试的方式,显然这样也更符合现在的快速迭代开发行情。当然了,提醒下大家==在正式环境要记得关闭Swagger,一来出于安全考虑二来也可以节省运行时内存==。
9.其他皮肤
可以导入不同的包实现不同的皮肤定义:
1 | <dependency> |
- bootstrap-ui 访问 http://localhost:8080/doc.html
1 | <!-- 引入swagger-bootstrap-ui包 /doc.html--> |

- Layui-ui 访问 http://localhost:8080/docs.html
1 | <!-- 引入swagger-ui-layer包 /docs.html--> |
- mg-ui 访问 http://localhost:8080/document.html
1 | <!-- 引入swagger-ui-layer包 /document.html--> |
7.异步、定时、邮件任务
1.异步任务
新建一个空spring boot项目,创建一个service包
创建一个类AsyncService
异步处理还是非常常用的,比如我们在网站上发送邮件,后台会去发送邮件,此时前台会造成响应不动,直到邮件发送完毕,响应才会成功,所以我们一般会采用多线程的方式去处理这些任务。
编写方法,假装正在处理数据,使用线程设置一些延时,模拟同步等待的情况;
1 |
|
编写controller包
编写AsyncController类,去写一个Controller测试一下
1 |
|
问题:我们如果想让用户直接得到消息,就在后台使用多线程的方式进行处理即可,但是每次都需要自己手动去编写多线程的实现的话,太麻烦了,我们只需要用一个简单的办法,在我们的方法上加一个简单的注解即可,如下:
- 给hello方法添加@Async注解;
1 | // 告诉Spring这是一个异步方法 |
- SpringBoot就会自己开一个线程池,进行调用!但是要让这个注解生效,还需要在主程序上添加一个注解@EnableAsync,开启异步注解功能;
1 | // 开启异步注解功能 |
- 重启测试,网页瞬间响应,后台代码依旧执行!
2.邮件任务
邮件发送,在日常开发中,使用非常的多,Springboot也帮我们做了支持!!!
- 邮件发送需要引入spring-boot-start-mail
- SpringBoot 自动配置MailSenderAutoConfiguration
- 定义MailProperties内容,配置在application.yml中
- 自动装配JavaMailSender
- 测试邮件发送
测试:
- 引入pom依赖
1 | <dependency> |
- 看它引入的依赖,可以看到 jakarta.mail
1 | <dependency> |
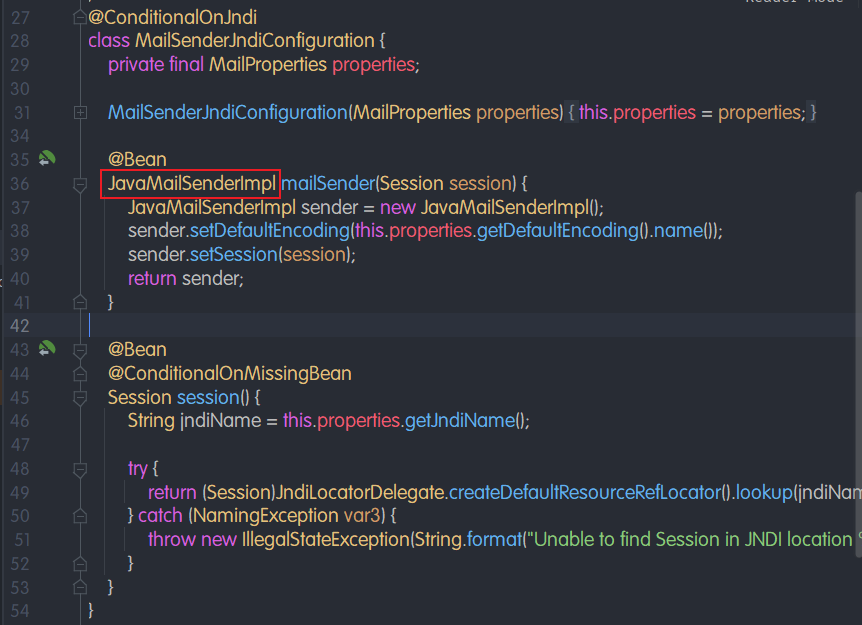
- 查看自动配置类:MailSenderAutoConfiguration

- 这个类中存在bean,JavaMailSenderImpl。
- 然后去看下配置文件
1 |
|
- 配置文件:
1 | spring.mail.username=2943357594@qq.com |
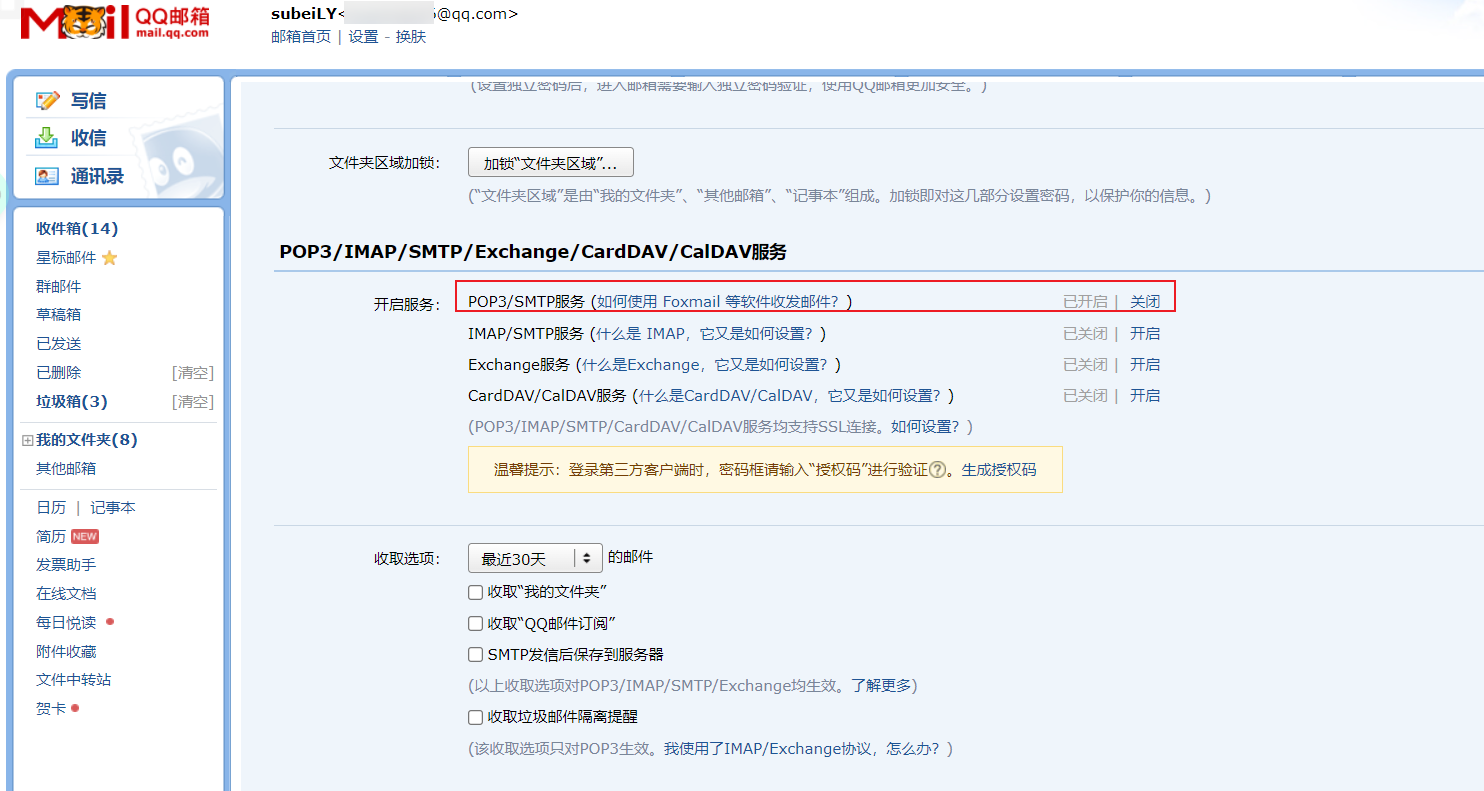
- 获取授权码:在QQ邮箱中的设置->账户->开启pop3和smtp服务。
- Spring单元测试
1 |
|
- 查看邮箱,邮件接收成功!

在后期开发中,只需要使用Thymeleaf进行前后端结合即可开发自己网站邮件收发功能了!
3.定时任务
项目开发中经常需要执行一些定时任务,比如需要在每天凌晨的时候,分析一次前一天的日志信息,Spring为我们提供了异步执行任务调度的方式,提供了两个接口。
- TaskExecutor接口
- TaskScheduler接口
两个注解:
- @EnableScheduling
- @Scheduled
cron表达式:
| 字段 | 允许值 | 允许的特殊字符 |
|---|---|---|
| 秒 | 0-59 | ,-*/ |
| 分 | 0-59 | ,-*/ |
| 小时 | 0-23 | ,-*/ |
| 日期 | 1-31 | ,-*?/L W C |
| 月份 | 1-12 | ,-*/ |
| 星期 | 0-7 或 SUN-SAT 0,7是SUN | ,-*?/L C # |
| 特殊字符 | 代表含义 |
|---|---|
| , | 枚举 |
| - | 区间 |
| * | 任意 |
| / | 步长 |
| ? | 日/星期冲突匹配 |
| L | 最后 |
| W | 工作日 |
| C | 和calendar联系后计算过的值 |
| # | 星期,4#2,第二个星期三 |
测试步骤:
- 创建一个ScheduledService
- 里面存在一个hello方法,他需要定时执行,怎么处理呢?
1 |
|
- 这里写完定时任务之后,需要
在主程序上增加@EnableScheduling开启定时任务功能。
1 | // 开启异步注解功能 |
- 详细了解下cron表达式:http://www.bejson.com/othertools/cron/
- 常用的表达式:
1 | (1)0/2 * * * * ? 表示每2秒 执行任务 |
8.富文本编辑器
1.简介
思考:我们平时在博客园,或者CSDN等平台进行写作的时候,有同学思考过他们的编辑器是怎么实现的吗?
- 在博客园后台的选项设置中,可以看到一个文本编辑器的选项:

其实这个就是富文本编辑器,市面上有许多非常成熟的富文本编辑器,比如:
Editor.md——功能非常丰富的编辑器,左端编辑,右端预览,非常方便,完全免费
wangEditor——基于javascript和css开发的 Web富文本编辑器, 轻量、简洁、界面美观、易用、开源免费。
TinyMCE——TinyMCE是一个轻量级的基于浏览器的所见即所得编辑器,由JavaScript写成。它对IE6+和Firefox1.5+都有着非常良好的支持。功能齐全,界面美观,就是文档是英文的,对开发人员英文水平有一定要求。
百度ueditor——UEditor是由百度web前端研发部开发所见即所得富文本web编辑器,具有轻量,功能齐全,可定制,注重用户体验等特点,开源基于MIT协议,允许自由使用和修改代码,缺点是已经没有更新了
kindeditor——界面经典。
Textbox——Textbox是一款极简但功能强大的在线文本编辑器,支持桌面设备和移动设备。主要功能包含内置的图像处理和存储、文件拖放、拼写检查和自动更正。此外,该工具还实现了屏幕阅读器等辅助技术,并符合WAI-ARIA可访问性标准。
CKEditor——国外的,界面美观。
quill——功能强大,还可以编辑公式等
simditor——界面美观,功能较全。
summernote——UI好看,精美
jodit——功能齐全
froala Editor——界面非常好看,功能非常强大,非常好用(非免费)
总之,目前可用的富文本编辑器有很多……这只是其中的一部分。
2.Editor.md
- 这里使用的就是
Editor.md,作为一个资深码农,Mardown必然是我们程序猿最喜欢的格式,看下面,就爱上了!
可以在官网下载它:https://pandao.github.io/editor.md/ , 得到它的压缩包!
解压以后,在
examples目录下面,可以看到他的很多案例使用!学习,其实就是看人家怎么写的,然后进行模仿就好了!可以将整个解压的文件导入至我们的项目,将一些无用的测试和案例删掉即可!
3.基础工程搭建
数据库设计
article:文章表
| 字段 | 备注 | |
|---|---|---|
| id | int | 文章的唯一ID |
| author | varchar | 作者 |
| title | varchar | 标题 |
| content | longtext | 文章的内容 |
建表SQL:
1 | use springboot; |
基础项目搭建
- 建一个SpringBoot项目配置。
1 | spring: |
1 | <dependency> |
- 实体类:
1 | // 文章类 |
3、mapper接口:
1 |
|
1 |
|
- 既然已经提供了 myBatis 的映射配置文件,自然要告诉 spring boot 这些文件的位置
1 | # 指定myBatis的核心配置文件与Mapper映射文件 |
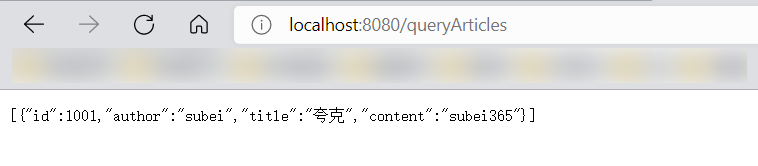
- 编写一个Controller测试下,是否ok;
1 |
|
4.文章编辑整合
导入 editor.md 资源 ,删除多余文件。
编辑文章页面 editor.html、需要引入jQuery;
1 |
|
- 编写Controller,进行跳转,以及保存文章
1 |
|
图片上传问题
- 前端js中添加配置
1 | // 图片上传 |
- 后端请求,接收保存这个图片, 需要导入 FastJson 的依赖!
1 | // 博客图片上传问题 |
3、解决文件回显显示的问题,设置虚拟目录映射!在我们自己拓展的MvcConfig中进行配置即可!
1 |
|
表情包问题
- 自己手动下载,emoji 表情包,放到图片路径下:

- 修改editormd.js文件
1 | // Emoji graphics files url path |
5.文章展示
- Controller 中增加方法
1 |
|
- 编写页面 article.html
1 |
|
- 重启项目,访问进行测试!大功告成!
9.整合Dubbo+Zookeeper
1.分布式理论
什么是分布式系统?
- 在《分布式系统原理与范型》一书中有如下定义:“分布式系统是若干独立计算机的集合,这些计算机对于用户来说就像单个相关系统”;
- 分布式系统是由一组通过网络进行通信、为了完成共同的任务而协调工作的计算机节点组成的系统。分布式系统的出现是为了用廉价的、普通的机器完成单个计算机无法完成的计算、存储任务。其目的是利用更多的机器,处理更多的数据。
分布式系统(distributed system)是建立在网络之上的软件系统。
- 首先需要明确的是,只有当单个节点的处理能力无法满足日益增长的计算、存储任务的时候,且硬件的提升(加内存、加磁盘、使用更好的CPU)高昂到得不偿失的时候,应用程序也不能进一步优化的时候,我们才需要考虑分布式系统。
- 因为,分布式系统要解决的问题本身就是和单机系统一样的,而由于分布式系统多节点、通过网络通信的拓扑结构,会引入很多单机系统没有的问题,为了解决这些问题又会引入更多的机制、协议,带来更多的问题。
- DUBBO官网:https://dubbo.apache.org/zh/
- 随着互联网的飞速发展,Web应用的规模不断扩大,最终我们发现传统的垂直架构(单体)已经无法应对。分布式服务架构和流计算架构势在必行,迫切需要一个治理体系来保证架构的有序演进。
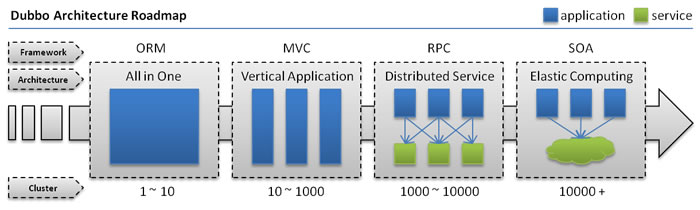
单体架构
- 当流量很低时,只有一个应用,所有的特性都部署在一起,减少部署节点和成本。此时,数据访问框架(ORM)是简化 CRUD 工作量的关键。

- 适用于小型网站,小型管理系统,将所有功能都部署到一个功能里,简单易用。
- 缺点:
- 1、性能扩展比较难
- 2、协同开发问题
- 3、不利于升级维护
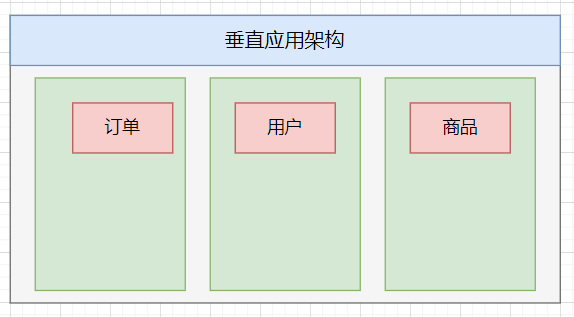
垂直架构
- 当流量变大时,添加单体应用实例并不能很好地加速访问,提高效率的一种方法是将单体应用拆分成离散的应用程序。此时,用于加速前端页面开发的Web框架(MVC)是关键。
- 通过切分业务来实现各个模块独立部署,降低了维护和部署的难度,团队各司其职更易管理,性能扩展
也更方便,更有针对性。 - 缺点: 公用模块无法重复利用,开发性的浪费
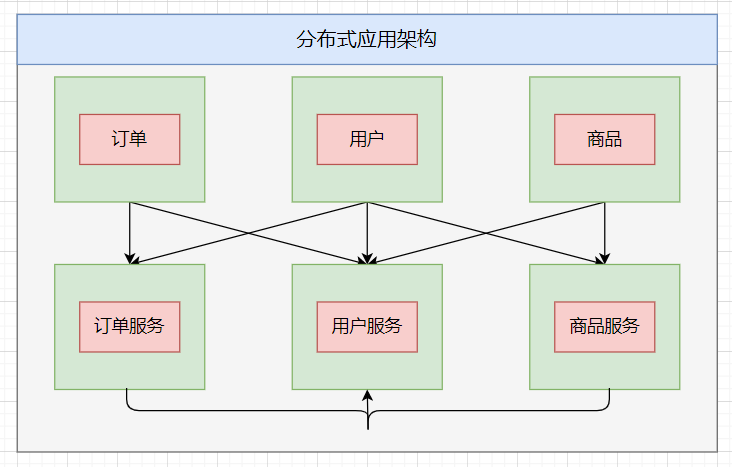
分布式服务架构
- 当垂直应用越来越多时,应用之间的交互是不可避免的,一些核心业务被提取出来,作为独立的服务,逐渐形成一个稳定的服务中心,这样前端应用就可以更好地响应多变的市场需求。迅速地。此时,用于业务重用和集成的分布式服务框架(RPC)是关键。
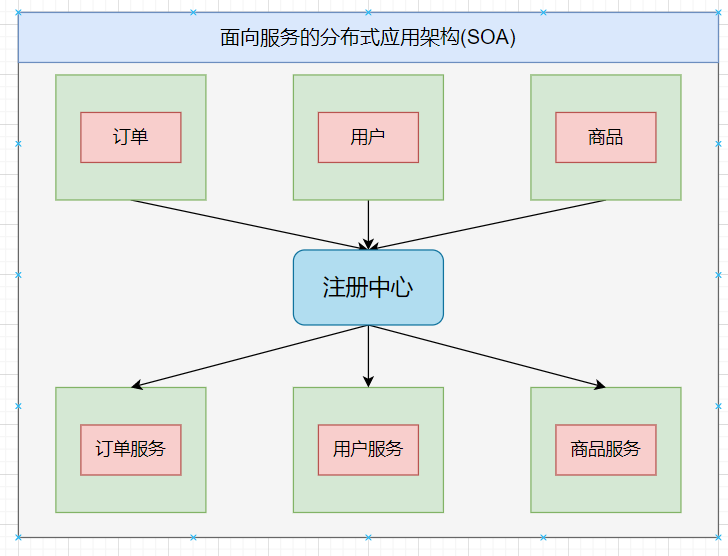
流计算架构
- 当服务越来越多时,容量评估变得困难,而且小规模的服务也经常造成资源浪费。为了解决这些问题,需要增加调度中心,根据流量对集群容量进行管理,提高集群的利用率。这时,用来提高机器利用率的资源调度和治理中心(SOA)是关键。
2.什么是RPC?
RPC【Remote Procedure Call】是指远程过程调用,像调用本地方法一样调用远程方法,是一种进程间通信方式,他是一种技术的思想,而不是规范。
它允许程序调用另一个地址空间(通常是共享网络的另一台机器上)的过程或函数,而不用程序员显式编码这个远程调用的细节。即程序员无论是调用本地的还是远程的函数,本质上编写的调用代码基本相同。
- 也就是说两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的函数/方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。
- 为什么要用RPC呢?
- 就是无法在一个进程内,甚至一个计算机内通过本地调用的方式完成的需求,比如不同的系统间的通讯,甚至不同的组织间的通讯,由于计算能力需要横向扩展,需要在多台机器组成的集群上部署应用。RPC就是要像调用本地的函数一样去调远程函数;
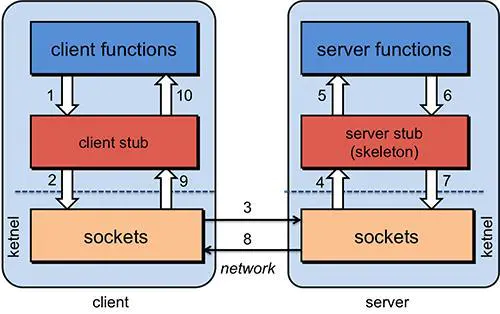
- 服务消费方(client)调用以本地调用方式调用服务;
- client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体;
- client stub找到服务地址,并将消息发送到服务端;
- server stub收到消息后进行解码;
- server stub根据解码结果调用本地的服务;
- 本地服务执行并将结果返回给server stub;
- server stub将返回结果打包成消息并发送至消费方;
- client stub接收到消息,并进行解码;
- 服务消费方得到最终结果。
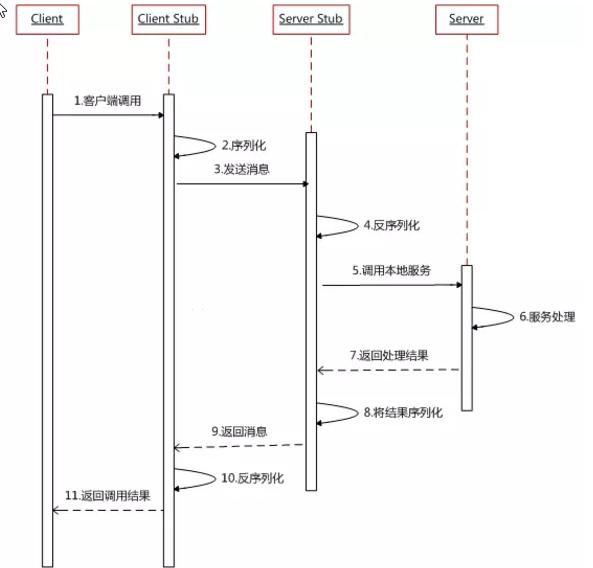
RPC两个核心模块:通讯,序列化。
3.什么是dubbo?
Apache Dubbo |ˈdʌbəʊ| 是一款高性能、轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。
- dubbo官网
- 了解Dubbo的特性;
- 查看官方文档
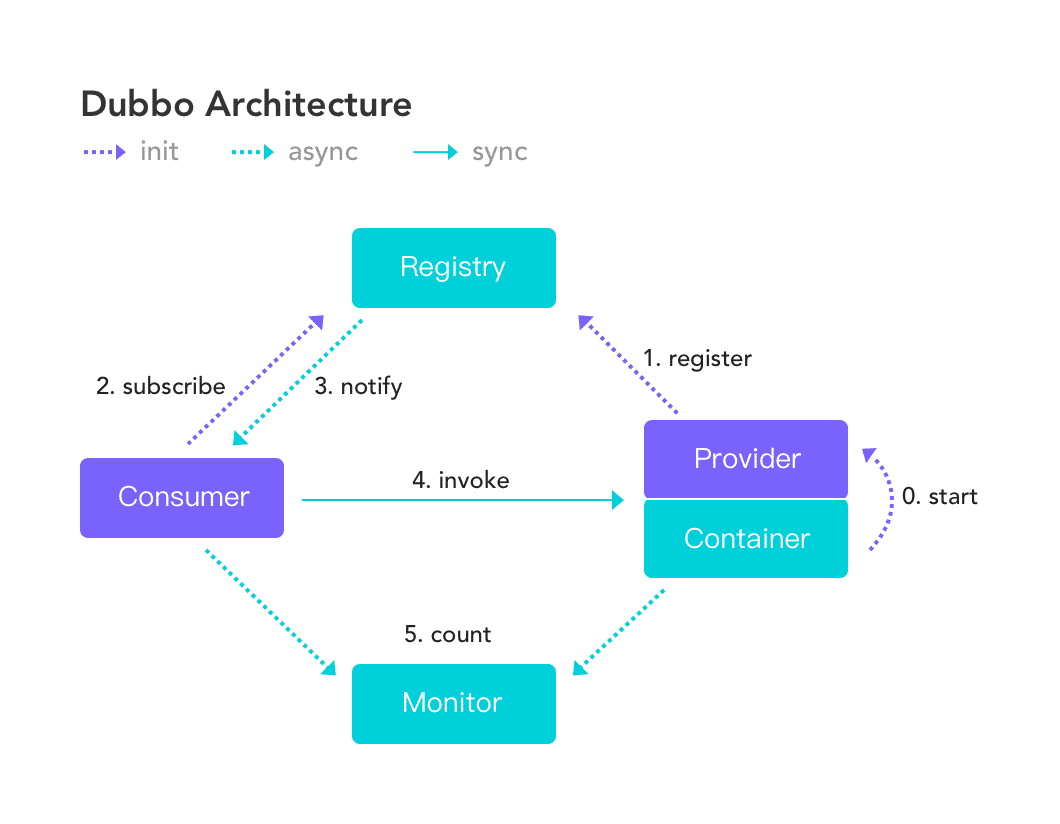
- 服务提供者(Provider):暴露服务的服务提供方,服务提供者在启动时,向注册中心注册自己提供的服务。
- 服务消费者(Consumer): 调用远程服务的服务消费方,服务消费者在启动时,向注册中心订阅自己所需的服务,服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
- 注册中心(Registry):注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
- 监控中心(Monitor):服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
- 调用关系说明
- 服务容器负责启动,加载,运行服务提供者。
- 服务提供者在启动时,向注册中心注册自己提供的服务。
- 服务消费者在启动时,向注册中心订阅自己所需的服务。
- 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
- 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
- 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
Dubbo的基本要求
- 在大规模服务出现之前,应用程序可能只是通过 RMI 或 Hessian 暴露或引用远程服务,通过配置服务 URL 进行调用,通过 F5 等硬件完成负载均衡。
- 当服务越来越多,配置服务URL变得非常困难,F5硬件负载均衡器的单点压力也越来越大。此时,需要一个服务注册中心来动态注册和发现服务,使服务的位置透明化。通过在消费者端获取服务提供者地址列表,可以实现软负载均衡和Failover,减少对F5硬件负载均衡器的依赖和部分成本。
- 当事情进一步发展时,服务依赖变得如此复杂,以至于它甚至无法告诉之前启动哪些应用程序,甚至架构师也无法完全描述应用程序架构关系。这时就需要自动绘制应用程序的依赖关系图,帮助架构师理清关系。
- 然后,流量变得更重,服务的容量问题暴露出来,需要多少台机器来支持这个服务?什么时候应该加机器?要解决这些问题,首先要将每天的服务调用量和响应时间量作为容量规划的参考。二、动态调整权重,增加一台在线机器的权重,并记录响应时间的变化,直到达到阈值,记录此时的访问次数,然后将此访问次数乘以总机器数计算反过来的能力。
更多参考:网页。
4.Dubbo环境搭建
- 点进dubbo官方文档,推荐我们使用Zookeeper注册中心!
- 什么是zookeeper呢?可以查看官方文档!

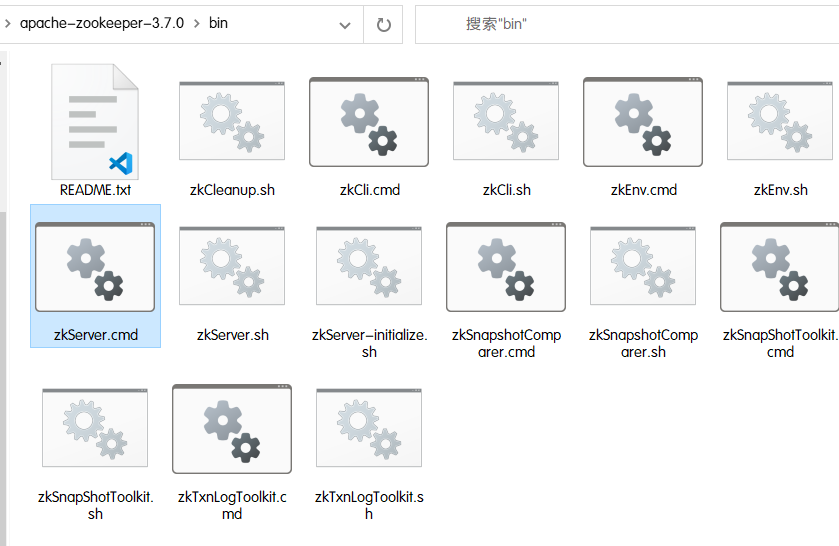
window下安装zookeeper
- 参考教程:菜鸟教程
可能遇到问题:闪退!
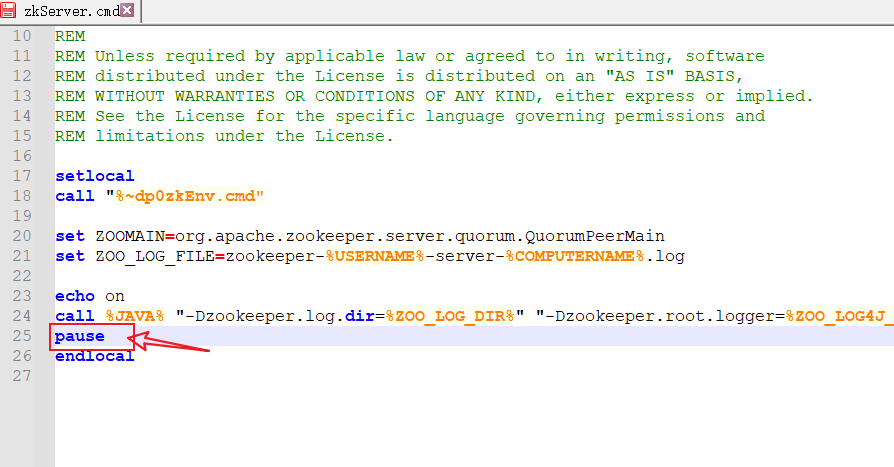
- 解决方案:编辑zkServer.cmd文件末尾添加
pause。这样运行出错就不会退出,会提示错误信息,方便找到原因。
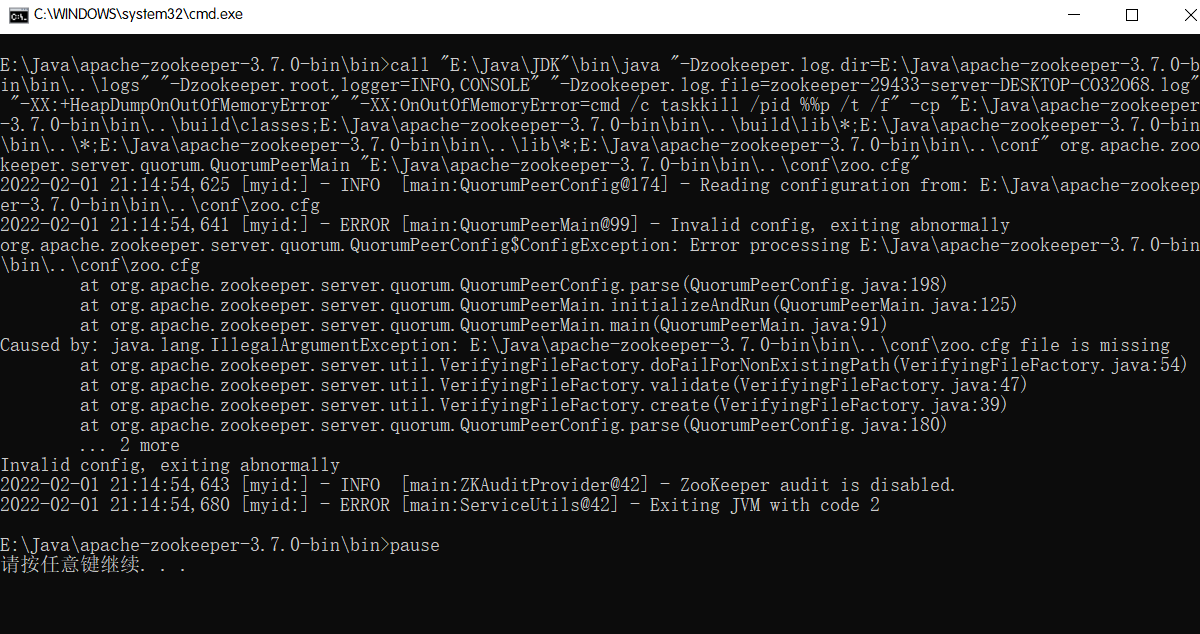
报错:
错误: 找不到或无法加载主类 org.apache.zookeeper.server.quorum.QuorumPeerMain
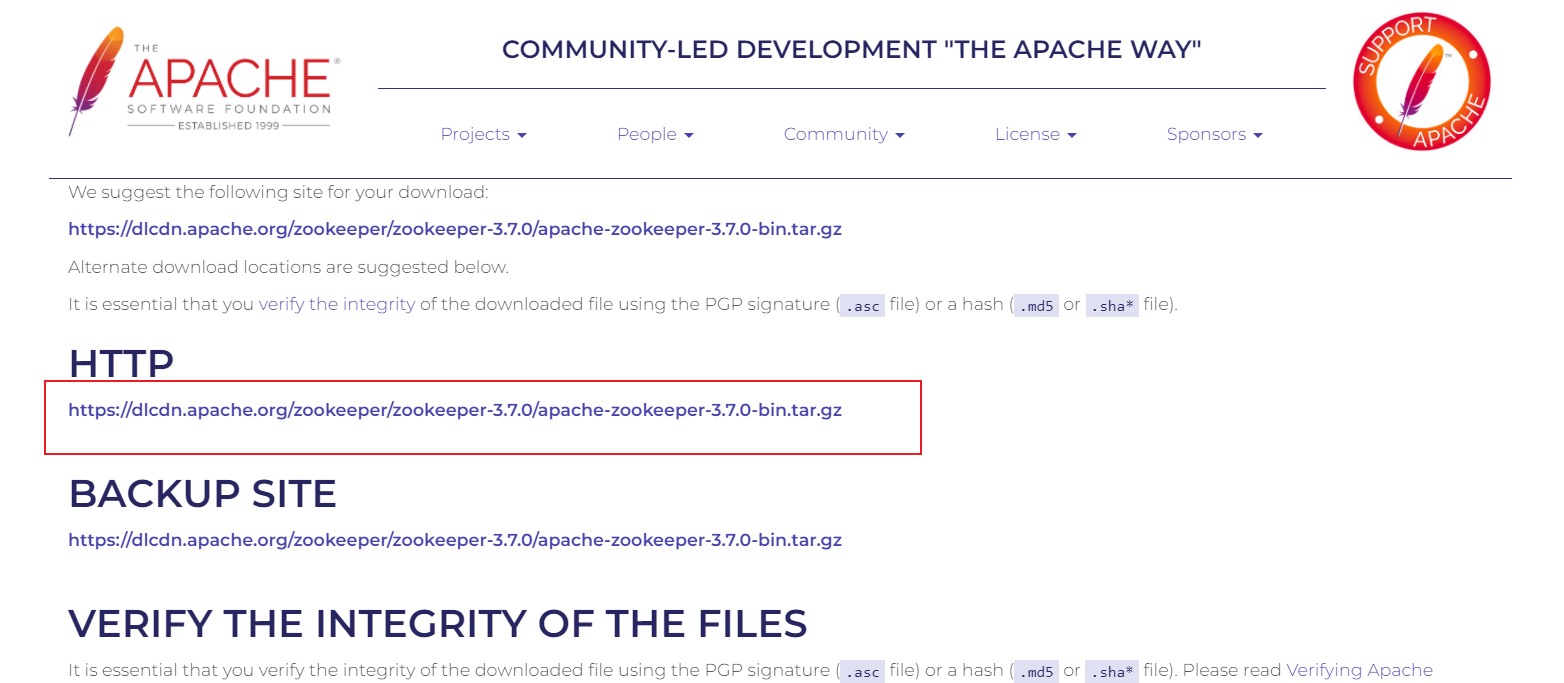
- 下载编译后的二进制的包,就好了。地址:https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz
- 将conf目录下的zoo_sample.cfg文件,复制一份,重命名为zoo.cfg:
- 在安装目录下面新建一个空的 data 文件夹和 log 文件夹:
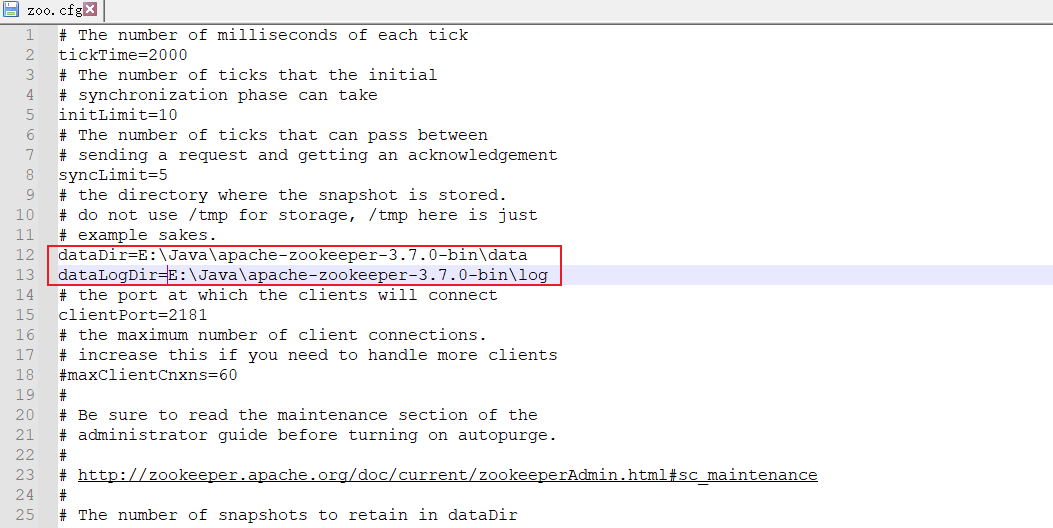
- 修改 zoo.cfg 配置文件,将 dataDir=/tmp/zookeeper 修改成 zookeeper 安装目录所在的 data 文件夹,再添加一条添加数据日志的配置(需要根据自己的安装路径修改)。
- 修改完成后再次双击 zkServer.cmd 启动程序:
Zookeeper启动失败:Unexpected exception, exiting abnormally java.net.BindException: Address alr
- 这是2181端口被占用导致的,需要结束占用2181端口的进程。
- 进去命令提示符之后,输入“netstat -aon | findstr 2181”命令,按回车键,如下图所示:

- 打开任务管理器,显示进程的pid之后,找到pid为19236的进程,点击结束进程。
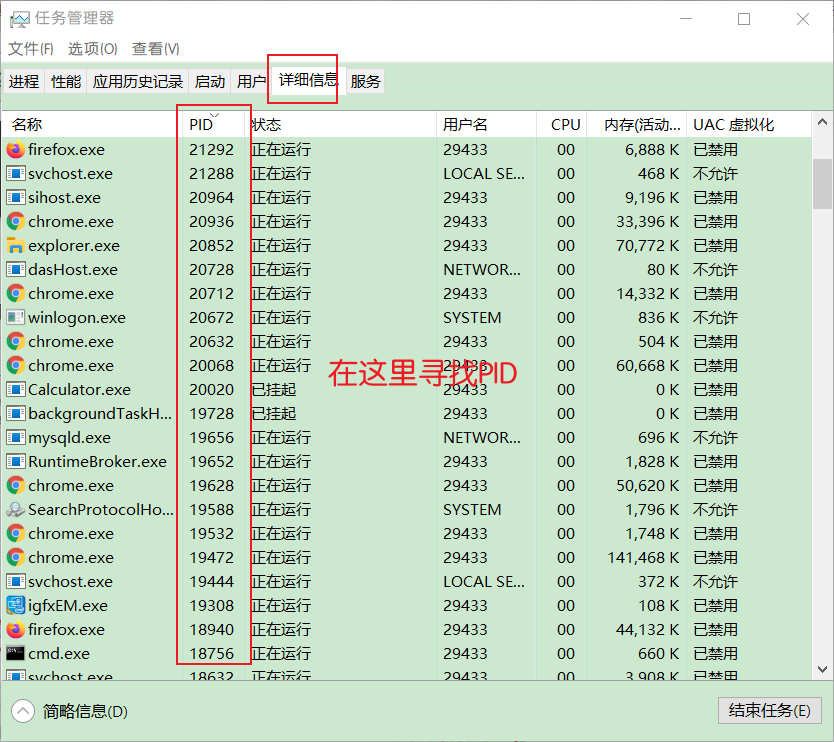
- 结束进程之后,再次运行项目,就正常运行了。
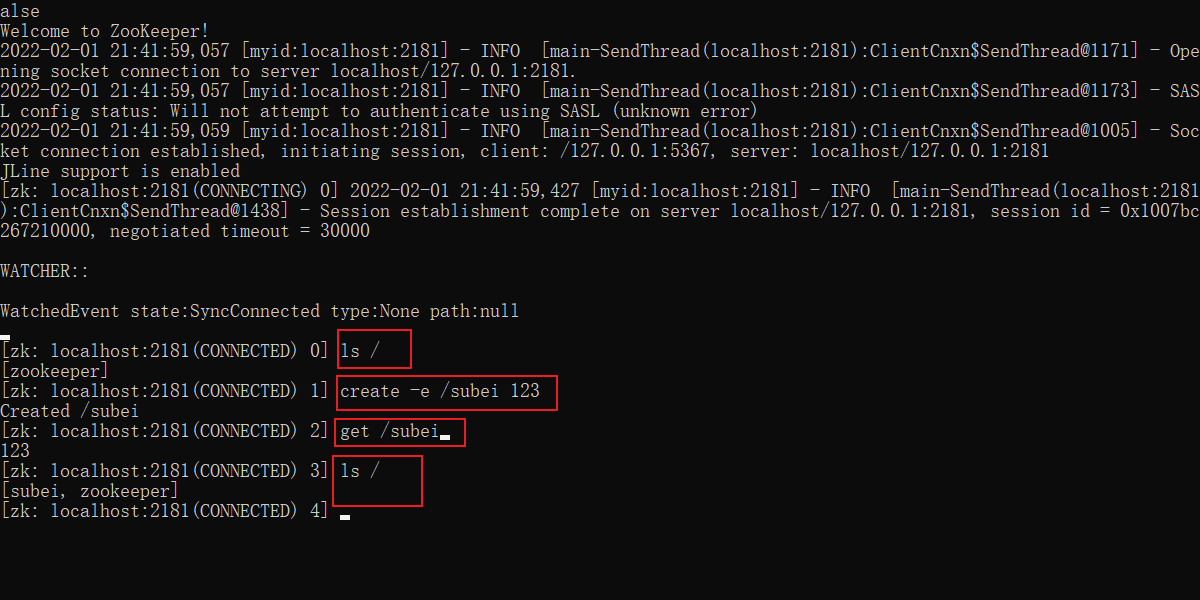
- 测试,双击zkCli.cmd 启动客户端。
ls /:列出zookeeper根下保存的所有节点。create –e /test 123:创建一个test节点,值为123。get /test:获取/test节点的值。
5.window下安装dubbo-admin
- dubbo本身并不是一个服务软件。它其实就是一个jar包,能够帮你的java程序连接到zookeeper,并利用zookeeper消费、提供服务。
- 但是为了让用户更好的管理监控众多的dubbo服务,官方提供了一个可视化的监控程序dubbo-admin,不过这个监控即使不装也不影响使用。
- 下载dubbo-admin
- 解压进入目录
- 修改 dubbo-admin-master-0.2.0\dubbo-admin\src\main\resources\application.properties 指定zookeeper地址
1 | server.port=7001 |
- 在项目目录下打包dubbo-admin
1 | mvn clean package -Dmaven.test.skip=true |
- 过程有点慢,需要耐心等待!直到成功!
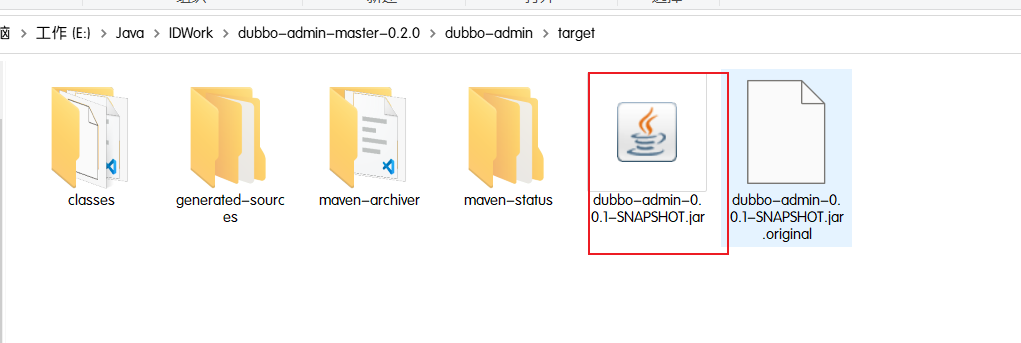
- 执行dubbo-admin\target下的dubbo-admin-0.0.1-SNAPSHOT.jar
1 | java -jar dubbo-admin-0.0.1-SNAPSHOT.jar |
- 注意:==zookeeper的服务一定要打开==!
- 执行完毕,去访问一下 http://localhost:7001/,这时候需要输入登录账户和密码,都是默认的`root-root`;登录成功后,查看界面。
安装完成!
新版实现
下载代码:
git clone https://github.com/apache/dubbo-admin.git在
dubbo-admin-server/src/main/resources/application.properties中指定注册中心地址构建
mvn clean package -Dmaven.test.skip=true
启动
mvn --projects dubbo-admin-server spring-boot:run
或者cd dubbo-admin-distribution/target; java -jar dubbo-admin-0.1.jar
访问
http://localhost:8080
不太稳定,启动失败!!!
6.框架搭建
- 启动zookeeper!
- 双击 zkServer.cmd 启动程序!
- IDEA创建一个空项目;
- 创建一个模块,实现服务提供者:provider-server,选择web依赖即可;
- 项目创建完毕,写一个服务,比如卖票的服务;
编写接口:
1 | package com.github.service; |
编写实现类:
1 | package com.github.service; |
- 创建一个模块,实现服务消费者:consumer-server,选择web依赖即可
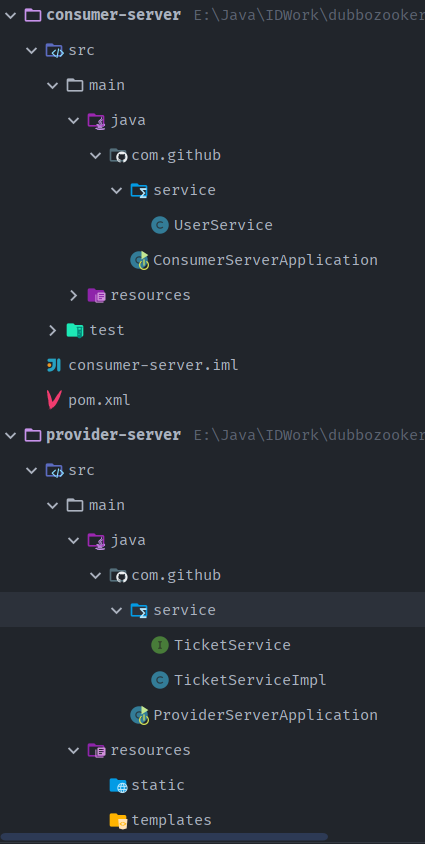
- 项目创建完毕,写一个服务,比如用户的服务; 编写service
1 | package com.github.service; |
7.服务提供者
- 将服务提供者注册到注册中心,需要整合Dubbo和zookeeper,所以需要导包。
- 从dubbo官网进入github,看下方的帮助文档,找到dubbo-springboot,找到依赖包。
1 | <!-- https://mvnrepository.com/artifact/org.apache.dubbo/dubbo-spring-boot-starter --> |
- zookeeper的包我们去maven仓库下载,zkclient;
1 | <!-- https://mvnrepository.com/artifact/com.github.sgroschupf/zkclient --> |
- zookeeper及其依赖包,解决日志冲突,还需要剔除日志依赖;
1 | <!-- https://mvnrepository.com/artifact/org.apache.curator/curator-framework --> |
- 在springboot配置文件中配置dubbo相关属性!
1 | # 当前应用名字 |
- 在service的实现类中配置服务注解,发布服务!注意导包问题。
1 | package com.github.service; |
逻辑理解:应用启动起来,dubbo就会扫描指定的包下带有@component注解的服务,将它发布在指定的注册中心中!
8.消费者
- 导入依赖,和之前的依赖一样;
1 | <!-- 导入依赖:Dubbo + Zookeeper --> |
- 配置参数
1 | # 当前应用名字 |
- 本来正常步骤是需要将服务提供者的接口打包,然后用pom文件导入,这里使用简单的方式,直接将服务的接口拿过来,路径必须保证正确,即和服务提供者相同;
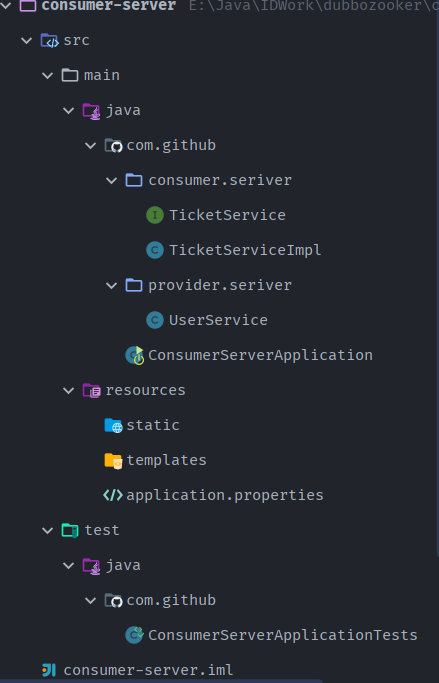
- 完善消费者的服务类
1 | package com.github.provider.seriver; |
- 测试类
1 | import com.github.provider.seriver.UserService; |
- 启动测试
- 开启zookeeper
- 打开dubbo-admin实现监控【可以不用做】
- 开启服务者
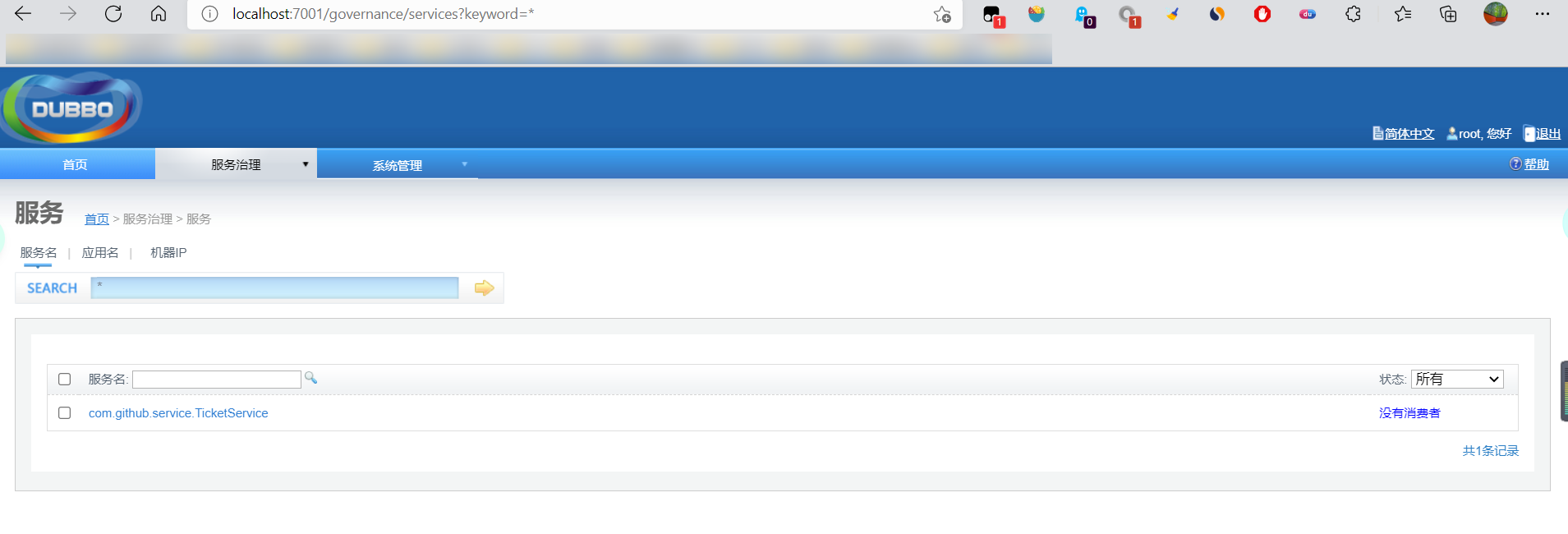
- 消费者消费测试
SpingBoot + dubbo + zookeeper实现分布式开发的应用,其实就是一个服务拆分的思想!!!








